Есть у меня одна совсем маленькая инсталляция – сервер Veeam Backup and Replication и отдельный Linux прокси с репозиторием. Бэкапируется не многим больше двадцати машин и, как можно догадаться из заголовка, резервные копии проверяются на работоспособность с помощью SureBackup.
Основой для написания поста поступило периодическое возникновение ошибок при выполнении задач SureBackup. Практически в каждый запуск задачи одна или несколько машин не проверялись, а в задаче фигурировала не очень детальная ошибка: “Registering. Error: One or more errors occurred”.
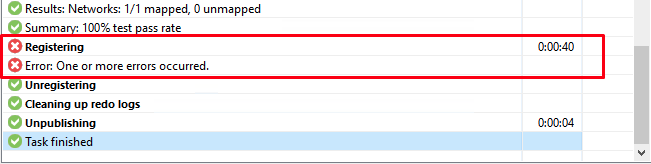
Под катом немного процесса диагностики и решение.
В первую очередь были опробованы несколько вариантов, которые не принесли результата:
- Разнесение задач SureBackup по времени;
- Изменения количества одновременно проверяемых VM вплоть до одной за раз;
- Манипуляции с количеством выделяемых ресурсов для проверяемых VM.
Пришлось копать глубже. Для начала я проверил журнал событий в vCenter, где запускаются проверяемые машины:
7:01:32 Creating vm_vmik_4de8c2f8019e4b3582b44b494d881cd9 on esxi7-01.vmik.lab
7:01:32 Task: Register virtual machine
7:02:07 Removed vm_vmik_4de8c2f8019e4b3582b44b494d881cd9 on esxi7-01.vmik.labПо логам видно, что виртуальная машина публикуется, а через ~30 секунд удаляется из окружения vSphere.
При этом в логе MountClient проверяемой VM можно отметить следующие события в это же временной промежуток:
cli | Thread started. Thread id: 10472, parent id: 9464, role: Remote VFS Server (worker: 4)
vfs | Remote VFS Server (worker: 4): Waiting NFS server connection
vfs | Waiting for clients.
cli | Thread started. Thread id: 9360, parent id: 9464, role: Remote VFS Server (worker: 6)
vfs | Remote VFS Server (worker: 6): Waiting NFS server connection
vfs | Waiting for clients.30 секунд ничего не происходит, а затем:
cli | Next client command: [disconnect].
vfs | Stopping VFS server.
vfs | Remote VFS Server (worker: 6): Timed out to wait connection from the NFS server.
cli | Thread finished. Role: 'Remote VFS Server (worker: 6)'.
vfs | Remote VFS Server (worker: 4): Timed out to wait connection from the NFS server.
cli | Thread finished. Role: 'Remote VFS Server (worker: 4)'.
vfs | Remote VFS Server (worker: 2): Timed out to wait connection from the NFS server.
cli | Thread finished. Role: 'Remote VFS Server (worker: 2)'.
vfs | Remote VFS Server (worker: 0): Timed out to wait connection from the NFS server.Timed out to wait connection from the NFS server. Уже что-то и наводит на мысль. Смотрим дальше.
В логах самой задачи SureBackup (task) можно найти следующие записи:
Error A specified parameter was not correct: path (Veeam.Backup.ViSoap.ViServiceFaultException)
Error VimApi.InvalidArgumentОшибка не совсем говорящая, однако, можно найти KB VMware, где описывается вероятная причина возникновения:
This issue occurs when the destination host cannot read the virtual machine file.
For example, when the datastore cannot be accessed from the host.
О том, как работает SureBackup я писал ранее здесь и здесь, но если коротко, то к гипервизору ESXi подключается NFS хранилище, которое презентуется с Veeam vPowerNFS сервера. На хранилище размещаются виртуальные машины, опубликованные напрямую с файлов резервных копий. Далее эти машины иvпортируются в инфраструктуру vSphere и включаются для автоматической проверки.
С точки зрения VMware это обычный Datastore с виртуальными машинами, с точки зрения Veeam немного сложнее, но в данном случае это не столь важно.
Конфигурация vPowerNFS выполняется на этапе создания, либо редактирования репозитория в секции Mount Server:
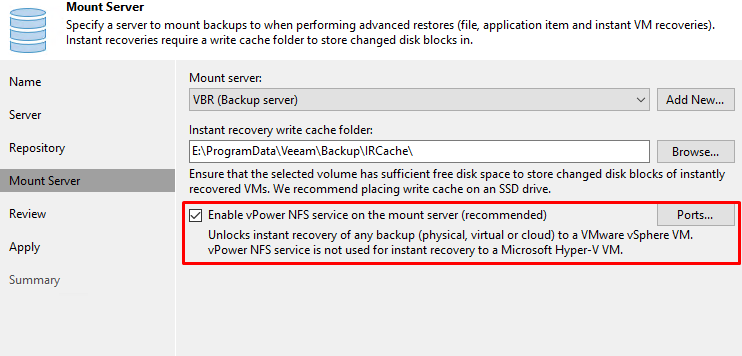
Mount Server в свою очередь размещается на системах под управлением MS Windows. В моей инфраструктуре это был только управляющий сервер Veeam Backup and Replication, соответственно Mount Server и vPower NFS разместились там же.
Затем я проверил статус vPower NFS хранилища в vCenter, и обратил внимание на повторяющиеся ошибки, которые возникали только в моменты выполнения задач SureBackup:
Target:
esxi7-01.vmik.lab
Description:
Datastore VeeamBackup_vbr.vmik.lab mounted on host esxi7-01.vmik.lab
was inaccessible. The condition was cleared and the datastore is now accessible
Event Type Description:
This event is logged when a datastore connectivity was restored. The host can have the following storage access failures: All Paths Down (APD) and Permanent Device Loss (PDL). Datastore was shown as unavailable/inaccessible in storage view.
Possible Causes:
A datastore on this host was inaccessible. The condition was cleared and the datastore is now accessible.Все указывает на проблемы с хранилищем, которое подключается к хосту с vPower NFS сервера. Становятся очевидными причины сбоя задач, но все еще не очевидна причина пропадания доступа хоста к NFS серверу.
В первую очередь, конечно же, было проверено все, что связано с сетью, но Veeam NFS server находится в той же сети, что и хосты ESXi, между ними нет маршрутизации, а сами каналы стабильные.
При дальнейшем рассмотрении в голову пришла мысль, что, возможно, Mount серверу не хватает ресурсов для выполнения операций и эта мысль была верная.
Серверу VBR, по совместительству vPower NFS серверу, еще и серверу с MS SQL Express в одном лице, было выделено всего 2vCPU.
Если обратиться к документации, можно легко определить минимальные рекомендации по сайзингу:
CPU: x86-64 processor (minimum 4 cores recommended);
Memory: 4 GB RAM plus 500 MB RAM for each enabled job. Memory consumption varies according to the number of VMs in the job, size of VM metadata, size of production infrastructure, and so on.
В моем случае налицо ошибка в изначальной конфигурации. Несмотря на то, что для выполнения операций резервного копирования ресурсов серверу было достаточно, дополнительный функционал в виде NFS сервера уже не мог обеспечить стабильную работу, что выражалось в виде сбойных задач SureBackup.
Возможно, я плохо искал, но не нашел в документации информации по рекомендуемому количеству процессорных ядер для серверов с ролями Mount Server и vPower NFS, поэтому для начала увеличил количество vCPU до 4 минимально рекомендуемых на сервере VBR.
Задачи SureBackup начали выполняться гораздо стабильнее, однако, при выполнении двух параллельных задач ошибки иногда продолжали возникать.
Количество vCPU было увеличено до 6, после чего ошибки SureBackup прекратились совсем, как при нескольких параллельных задачах, так и при большем количестве одновременно проверяемых VM.
В качестве заключения
Таким вот образом изначально неверный сайзинг может сказаться на работе задач Veeam.
При планировании инсталляции следует всегда прибегать к документации и стараться придерживаться рекомендуемых требований. Даже если кажется, что сервер в большинстве случаев простаивает, на нем нет никакой нагрузки, а инфраструктура совсем маленькая, это совсем не означает то, что выделенные ресурсы ему не понадобятся в моменты выполнения определенных операций.
Ну и конечно же, не стоит использовать сервер VBR в качестве Mount и vPower NFS серверов (это плохая практика!), для этого лучше подойдет отдельная машина, либо сервер с репозиторием, если он, конечно, под управлением Windows.
![]()