Время от времени приходится прибегать к процедуре замены дисков на нодах Nutanix серии NX, и хоть это и крайне простая операция, на некоторые моменты можно обратить внимание.
Внимание: при замене дисков стоит руководствоваться только официальным документом, в котором данная процедура детально описана, а также рекомендациями официальной технической поддержки.
Данная статья лишь дополнение с описанием того, что можно ожидать в процессе замены диска, а не непосредственная инструкция к действию.
Процедуры замены «обычных» дисков, задействованных для extent store и системных дисков, на которых располагается CVM, OPLOG, кэш и т.п. отличаются.
Итак, получив не самое приятное аварийное сообщение, обращаем внимание на список активных задач в Prism Element:

Система так же предупреждает, что ведется восстановление требуемого количества копий данных, определяемых параметром Replication Factor:

При включенном факторе репликации = 2 (RF2), выход из строя второго компонента в момент процедуры восстановления крайне нежелателен и может привести к последствиям.
Крайне не рекомендуется выполнять какие-либо действия (без рекомендации на то технической поддержки), которые могут повлиять на стабильность работы кластера, когда сообщение «Data Resiliency not possible» активно и общий статус кластера – «Critical».
Дожидаемся окончания процедуры вывода сбойного диска и восстановления корректного числа реплик. Вот теперь все выглядит неплохо:
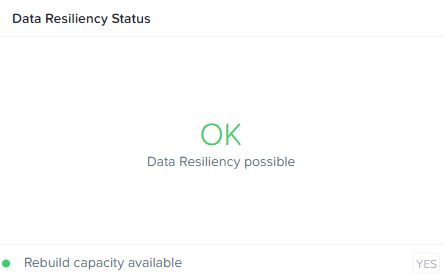
Общий дисковый объем кластера, соответственно, уменьшился на объем выведенного из работы диска.
Следующим шагом оформляем запрос в техническую поддержку на замену вышедшего из строя диска. Могут понадобиться следующие данные:
- Отчет NCC. Health – Actions – Run NCC Checks;
- Вывод команд df –h и list_disks с CVM, которая располагается на ноде, где вышел из строя диск.
После оформления запроса и получения диска для замены, определяем слот вышедшего из строя диска (если не сделано ранее) и производим физическую замену. Определить слот легко на закладке Hardware – Diagram в Prism Element:
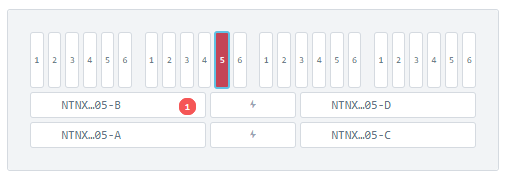
Диаграммы расположения компонентов – очень удобная вещь, легко понять, с каким из компонентов проблемы и где он расположен. В примере выше – сбойный диск на ноде B, в позиции 5.
Отправляемся в ЦОД, находим блок, в котором располагается сбойный диск, снимаем лицевую панель и идентифицируем диск, который, скорее всего, будет подсвечен красным. Изымаем старый диск и монтируем новый в соответствии с официальной инструкцией.
В процессе физической замены диска можно получить два сообщения, одно о том, что диск был изъят из системы, второе о том, что диск был добавлен в систему.
После замены диска, необходимо вернуться в Prism Element на страницу с диаграммами нод и выбрать замененный диск (скорее всего он до сих пор будет отмечен красным). Справа, ниже диаграммы, станет доступна кнопка «Repartition and Add».
Если случайно был выбран другой диск, который сейчас находится в работе, доступными для него функциями будут «Remove Disk», «Turn On/Off LED», трогать его не нужно.
После выбора диска и нажатия «Repartition and Add», диск некоторое время может находиться в статусе «Being Added»:
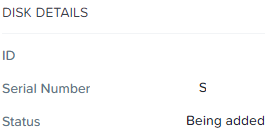
Через некоторое время диск будет подключен к CVM, размечен и включен в общий дисковый пул (если он один), а размер кластера увеличится на соответствующий объем. Так же по добавленному диску начнет выводиться информация относительно объема, заполняемости и т.п.
Данная процедура не оказывает влияния на доступность существующих данных, а всего лишь расширяет существующий дисковый пул.
После выполнения процедуры добавления диска в CVM, можно наблюдать, что он начинает заполняться данными:

В данном случае в работу включается Curator, который выполняет фоновую балансировку кластера, выравнивая заполняемость дисков в пуле, так же, можно заметить, что объем занятости остальных дисков может уменьшиться, однако это слабо заметно при большом их количестве.
В заключении следует выполнить проверку кластера с помощью NCC, убедиться, что все ошибки, связанные с выходом из строя диска, устранены, и поблагодарить техническую поддержку за содействие.
![]()