Хранить логи не только на самом оборудовании, но и удаленно, это всегда хорошая практика. Современные системы позволяют не просто хранить журналы оборудования, систем и сервисов, но также анализировать их и, при необходимости, информировать администраторов о наличии в логах записей, требующих внимания.
Большинство Linux систем используют rsyslog для отправки своих журналов в места их длительного хранения и Nutanix здесь не является исключением.
К сожалению, в отличии от интерфейса Prism Central, в котором настройка отправки журналов возможна из веб-интерфейса, аналогичной функции в Prism Element нет и потребуется прибегнуть к командной строке для настройки.
Ниже о том, как включить rsyslog в кластере Nutanix.
На данном сайте можно периодически встретить посты про Veeam, а можно про Nutanix. Но постов, совмещающих оба этих продукта, еще не было, несмотря на то, что повод уже очень давно есть.
Настало время исправить данный недочет и сделать пару резервных копий виртуальных машин Nutanix на базе гипервизора AHV с помощью VBR.
Ниже мы пройдемся по всем этапам настройки системного копирования, бэкапа и, конечно же, восстановления.
Резервное копирование с использованием Storage Snapshots – функция, поддерживаемая Veeam уже достаточно долгое время, но написать про то, как это работает и вообще зачем, руки так и не добирались.
Настало время исправить это упущение. Ниже мы посмотрим на то, как Veeam взаимодействует с СХД, как он выполняет процедуру бэкапа, и почему бэкап из снимков крайне удобен, и, в целом, желателен к использованию при возможности.
Nutanix пересматривает свою существующую сертификацию и, в дополнении к весеннему ребрендингу сертификации NCP и NCAP, которые превратились в NCP-MCI и NCAP-MCI, в ближайшее время ожидается много нового в плане сертификации и обучения.
Первое – станет доступен новый экзамен начального уровня, который сейчас находится на стадии бета-тестирования, NCA – NutanixCertifiedAssociate. Данный экзамен проверит базовые знания сдающего относительно функционирования решений Nutanix и базового администрирования.
Таким образом порядок сертификации будет выглядеть следующим образом – NCA – NCP – NCM – NPX.
В дополнение к существующему сертификационному треку Multicloud Infrastructure планируется добавить три новых. Общий список будет выглядеть вот так:
Digital HCI Services – Multicloud Infrastructure;
Data Center Services – Data Services, Security & Governance, Business Continuity;
В ближайшее время должны появиться еще два новых экзамена:
Nutanix Certified Professional – End User Computing (NCP-EUC) – развертывание систем VDI на базе решений Nutanix;
Nutanix Certified Professional – Data Services (NCP-DS) – Работа с Files, Objects и Volumes.
Кроме сертификации, на портале Nutanix University появились новые обучающие курсы и планы по обучению (группа курсов, связанных общей тематикой, или же Learning Plan).
В дополнении к существующим курсам Enterprise Cloud Administration (ECA) и Advanced Administration & Performance Management (AAPM), которые могут быть использованы для подготовки к экзаменам NCP и NCM, добавился курс Nutanix Hybrid Cloud Fundamentals, который покрывает основы AOS, управления кластером, хранением, защитой данных и т.д. Данный курс, очевидно, подготавливает к сдаче нового экзамена NCA.
И новые Learning Plans:
Nutanix Multicloud Infrastructure– включает в себя темы от конфигурирования кластера до оптимизации и траблшутинга. Однозначно полезен при подготовке к экзаменам Multicloud Infrastructure;
Enterprise Cloud Solutions – Группа онлайн-курсов по экосистеме Nutanix. Начиная от AOS, заканчивая такими решениями как Nutanix Mine и Karbon. Очевидно будет полезет при подготовке к экзаменам из треков DevOps и Data Center Services.
Вот такие, достаточно интересные и перспективные изменения, которые мотивируют изучать больше и сертифицироваться.
При этом стоит помнить, что онлайн-курсы на Nutanix University бесплатны и доступны для изучения в любой удобный момент.
Если говорить о разграничении прав доступа в Prism Element – базовом инструменте доступа и управления кластером Nutanix и его содержимым, то оно представлено всего тремя доступными ролями:
Viewer – пользователь имеет право просматривать содержимое всего кластера, но не может его изменять;
Cluster Admin – пользователь имеет право управлять всеми элементами кластера, но не может управлять пользователями;
User Admin – максимальные привилегии. Пользователь может управлять всеми элементами кластера, а также пользователями.
Данная схема работает хорошо, когда у кластера один администратор и не требуется каких-либо разграничений в доступе.
Но что делать, если, например, необходимо разграничить доступ более жестко и предоставить одной группе пользователей доступ к управлению одной частью виртуальных машин, а другой группе – ко второй?
К сожалению, малогибкие возможности Prism Element не позволяют осуществлять подобные разграничения и тут в дело вступает мощный инструмент по централизованному управлению и мониторингу кластеров Nutanix – Prism Central.
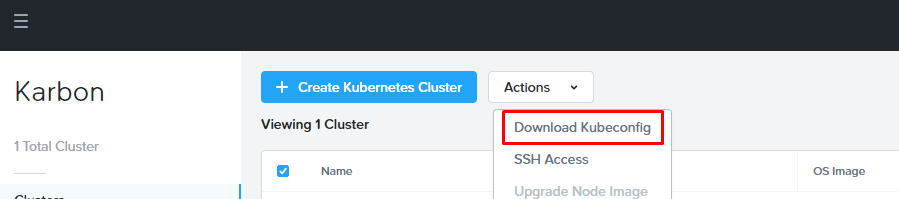
В процессе эксплуатации кластеров Kubernetes на базе Nutanix Karbon одним из первых моментов, с чем приходиться столкнуться – получение непосредственного доступа к управлению Kubernetes.
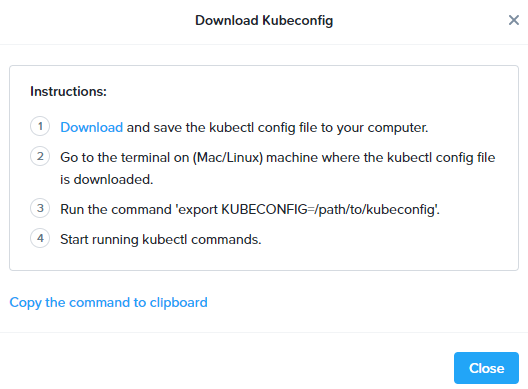
Сделать это достаточно просто. В интерфейсе Karbon необходимо выбрать требуемый кластер и с помощью пункта меню Actions загрузить файл Kubeconfig.
На машине, с которой планируется управление кластером, необходимо установить kubectl версии аналогичной той, которая развернута с помощью Nutanix Karbon. Далее, следуя инструкции разместить файл на машине, с которой планируется подключение к кластеру и использовать переменную KUBECONFIG, либо разместить файл в /home/user/.kube под именем config.
На этом можно было бы закончить, но здесь есть моменты, на которые стоит обратить внимание.
На днях посчастливилось протестировать Nutanix Karbon, который позволяет без каких-либо трудозатрат развернуть на площадке Nutanix готовый к использованию кластер Kubernetes.
Процесс развертывания крайне прост и через ~20-30 минут в моем распоряжении был готовый к использованию кластер.
Естественно, в первую очередь захотелось развернуть простейший «Hello World» из местного реестра на базе Harbor, и проверить работоспособность, но первый деплой был, как говорится, комом.
Одним из самых интересных нововведений в 10й версии Veeam для сервис-провайдеров, он же Veeam Cloud Connect, на мой взгляд является возможность выполнения репликации виртуальных машин клиента не только в выделенную со стороны сервис-провайдера виртуальную инфраструктуру VMware и Hyper-V, но и в облако под управлением vCloud Director.
Как по мне, это отличная возможность и для клиентов, и для сервис-провайдеров. Первые получают достаточно простой метод организации DR в своей компании, а вторые получают возможность предоставлять больше услуг своим клиентам и, тем самым, увеличивать свой доход.
Под катом мы пройдемся по этапам настройки репликации как на стороне сервис-провайдера, так и на стороне клиента.
Вышло в свет первое крупное обновление для Veeam BR 10, с номером билда 10.0.1.4854. Обновление включает ряд улучшений, исправление ранее найденных проблем, а также поддержку новых версий систем. Полностью с описанием обновления можно здесь.
Добавлена поддержка новых версий операционных систем, а также ПО:
Microsoft Windows 10 и Windows Server версии 2004;
Поддержка ядра Linux 5.7. Как для гостевых ОС, так и для систем, на которые будут установлены компоненты Veeam;
Поддержка RHEL 8.2/Oracle Linux 8.2/CentOS 8.2;
VMware vCloud Director 10.1;
Последняя версия Azure.
Управление резервным копированием AWS добавлено в консоль VBR (необходимо установить плагин).
Ряд изменений касается лицензирования, в частности относительно резервирования NAS для небольших объемов.
В дополнение ко всему заявлено более 1200 различных улучшений исправлений на основе запросов и отзывов пользователей продукта. Улучшена производительность UI, а также снижена нагрузка на конфигурационную базу данных.
Для обновления на данную версию необходима инсталляция VBR версии 9.5U3 и выше. Обновление 10a включает в себя кумулятивные патчи 1 и 2, которые вышли ранее.