Решил посвятить начало 2021 года вопросам защиты данных, доступности систем, репликации, и прочему повышению отказоустойчивости. Начнем, как можно понять из заголовка, с возможностей, которые предоставляет нам Nutanix.
Встроенная асинхронная репликация в AOS доступна «из коробки» и не требует дополнительного лицензирования, отчего является крайне привлекательным решением для повышения показателей доступности и сохранности данных.
О том, как это начать работать с асинхронной репликацией – ниже.
Прежде чем приступить к непосредственному обзору асинхронной репликации, быстро посмотрим на весь список предоставляемых возможностей из раздела Data Protection and Disaster Recovery:
- Async Replication;
- Application Consistent Snapshots;
- Self Service Restore;
- NearSync Replication;
- Sync Replication;
- Multiple Site DR;
- Metro Availability;
- Advanced Orchestration with Runbook Automation.
Первый и второй пункт данного списка доступны изначально и требуют только Starter лицензию AOS.
Все остальные возможности доступны при наличии лицензии Ultimate, либо при наличии лицензии Pro и дополнительно Adv Replication license addon.
С технологией синхронной репликации и Metro понятно, что они обеспечивают около нулевые значения RPO (Recovery Point Objective), а вот какие показатели RPO может обеспечить асинхронная репликация и NearSync и в чем их различие – стоит обратить внимание:
Async Replication:
Название говорит само за себя. Асинхронная репликация. Виртуальные машины, либо volume groups, копируются в другой кластер\облако с заданной в планировщике частотой. Минимальная частота запуска процесса данного типа репликации составляет один час, что позволяет обеспечить показатели RPO от 60 и более минут.
NearSync Replication:
В данном случае за основу берется технология Lightweight Snapshot – снимки уровня метаданных. Использование данной технологии позволяет обеспечить показатели RPO от 1 до 15 минут при асинхронной репликации.
Итого, для обеспечения показателей RPO ~0 используем Metro/Sync replication, для PRO 1-15 минут – NearSync, для RPO от одного часа и выше – Async.
Теперь займемся асинхронной репликацией
После того, как мы коротко рассмотрели, какая репликация вообще бывает в Nutanix, рассмотрим непосредственную процедуру настройки и запуска асинхронной репликации.
У меня есть два кластера – ntnx-ce и ntnx-ce-dr. Задача крайне простая: необходимо организовать репликацию выбранных виртуальных машин с кластера ntnx-ce в кластер ntnx-ce-dr чтобы иметь возможность запустить виртуальные машины на резервной площадке в случае сбоев на основной.
В целом, данную процедуру можно разбить на несколько этапов:
- Настройка Virtual IP на основном и резервном кластере, если это еще не было сделано ранее;
- Настройка сетей на резервном кластере, к которым будут подключены реплики виртуальных машин;
- Настройка файрволлов меджу кластерами. Должен присутствовать доступ по портам 2009 (Cerebro) и 2020 (Stargate);
- Выполнить процедуру добавления Remote Site как на основном кластере, так и на резервном;
- Создать Protection Domain (PD) и включить в него виртуальные машины, для которых необходима репликация, а также настроить планировщик с требуемыми параметрами RPO для ранее созданного PD;
- Наблюдать за процедурами репликации. При необходимости, протестировать.
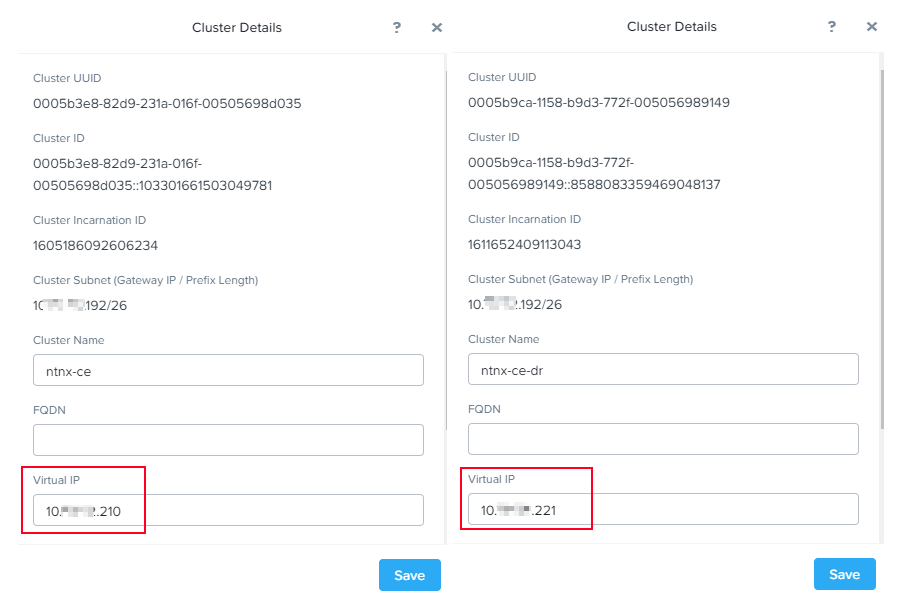
Шаг первый. Настройка Virtual IP:
Начнем с настройки Virtual IP на кластерах (хотя, данный пункт скорее всего выполнен).
Вызвать меню настройки можно кликнув по названию кластера в левом верхнем углу Prism Element:
Шаг второй. Создаем сети на резервном кластере:
Следующим шагом выполним настройку сетей. В моем тестовом кластере не так много сетей:
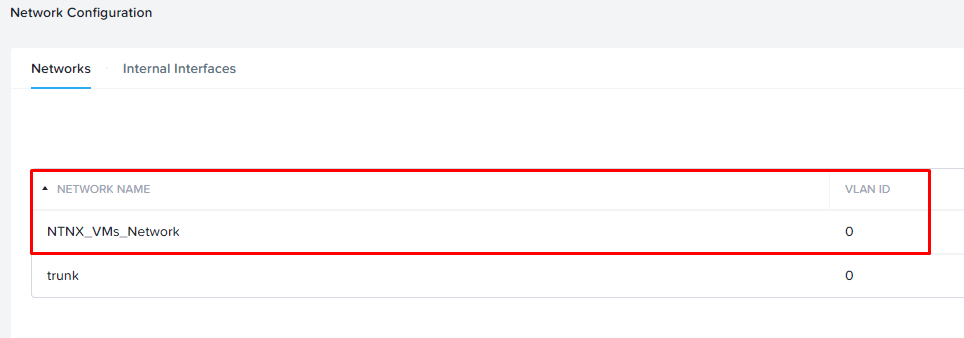
Все виртуальные машины подключены к сети NTNX_VMs_Network с VLAN ID = 0.
Поскольку мои кластера находятся в одной и той же сети, аналогичную сеть c тем же VLAN ID я создаю на резервном кластере:

Поскольку между моими кластерами нет никакого брандмауэра, шаг третий я пропускаю.
Шаг четвертый. Добавление Remote Site:
Переходим в меню Data Protection на основном кластере:

И выбираем пункт меню «+ Remote Site» в правом верхнем углу:
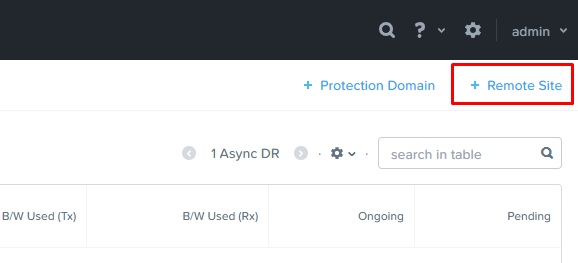
Данный пункт предложит выбрать, что мы добавляем в качестве резервной стороны – физический кластер, либо облако (AWS/Azure).
Я использую физический кластер (нет) и выбираю, соответственно, «Physical Cluster».
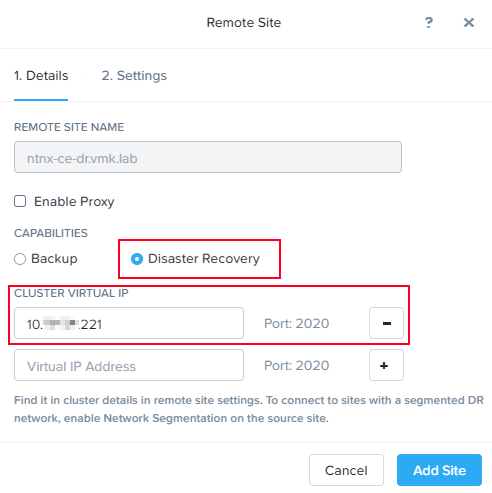
На закладке Details мы указываем Virtual IP резервного кластера, который был задан в первом шаге.
Поскольку мы планируем запускать асинхронную репликацию, выбираем пункт Disaster Recovery. Но, при необходимости, на удаленном кластере мы можем также хранить резервные копии виртуальных машин.
Переходим на закладку Settings.
Здесь имеется возможность настроить политики ограничений скорости резервного копирования, причем политики можно настроить достаточно тонко, например, выставить ограничение в определённое время суток определенных дней:
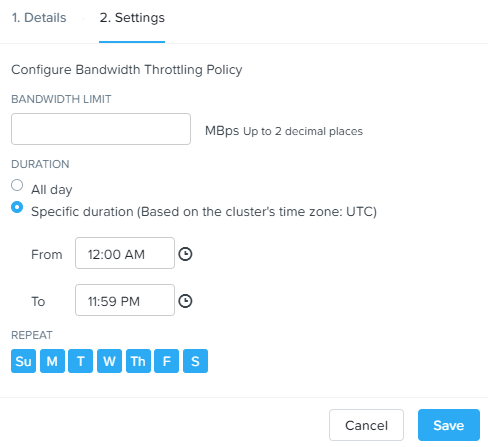
Сделать это можно выставив соответствующий переключатель Bandwidth Throttling и добавив соответствующую политику.
Имеется возможность включить компрессию трафика переключателем COMPRESS ON WIRE.
Следующим шагом в разделе Network Mapping необходимо настроить соответствие сетей.
Здесь все просто – виртуальные машины из указанной сети в Source Cluster будут подключены к сети, указанной в столбце Destination Cluster на резервной площадке.
В моем примере все виртуальны машины, подключенные к сети NTNX_VMs_Network будут подключены к сети с аналогичным названием на резервном кластере.
И последним шагом включается vStore Name Mapping. Здесь все аналогично настройке сетей. Виртуальные машины из контейнеров на основной площадке, будут размещаться в указанном контейнере на резервной площадке.
Соответствие контейнеров настраивается один к одному. Т.е. нельзя указать два контейнера на основном кластере и один контейнер на резервном.
Сверяем настройки и кликаем «Save»:
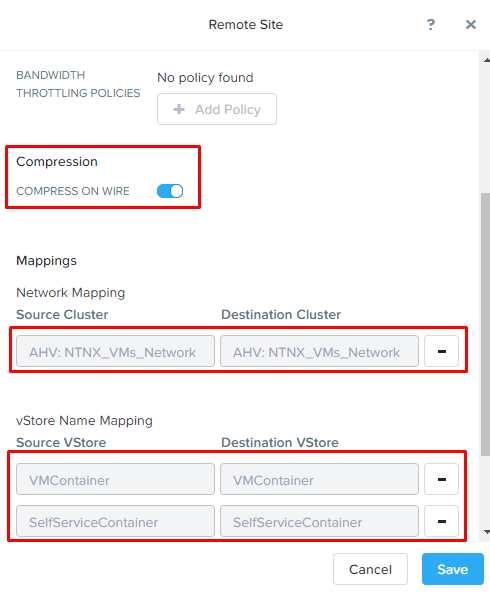
Теперь на закладке Remote Site основной площадки у нас отображается резервный кластер:

В нижней части экрана имеется кнопка «Test Connection», с помощью которой можно выполнить проверку соединения между площадками. Если запустить проверку на данном этапе, можно с легкостью получить ошибку «Connectivity to remote site is not normal»:
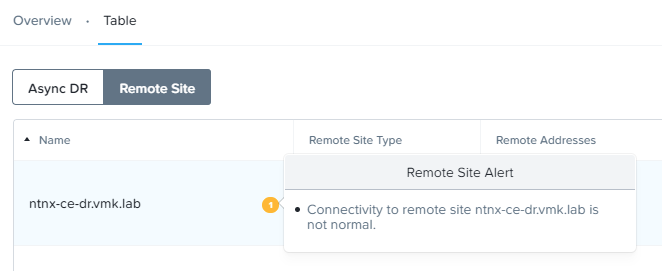
Если просмотреть ошибку, там же будет описано и решение «Configure the local site as a remote on the remote site». Ранее об этом было сказано.
Выполняем ту же самую процедуру по добавлению Remote Site на резервном кластере. Переходим в резервный кластер и в меню Data Protection кликаем «+ Remote Site»:

Здесь мы указываем название и Virtual IP основной площадки, с которой мы планируем настроить репликацию и кликаем «Add Site». Аналогичным образом настраиваем соответствие сетей и контейнеров.
Шаг пятый. Создаем Protection Domain (PD):
PD – группа виртуальных машин, которая реплицируется на удаленный кластер по заданному для данного домена расписанию.
Пара важных ограничений:
- Максимальное количество элементов в одном домене – 200. Это могут быть как VM, так и VG;
- Если виртуальная машина уже включена в один PD, включить в другой ее уже нельзя.
Теперь создадим новый Protection Domain. Делается это на закладке Data Protection. В правом верхнем углу, там же где кнопка добавления резервного кластера, имеется кнопка создания PD.
Выбираем «+ Protection Domain» – «Async DR». Загрузится диалоговое окно, состоящее из трех этапов:
- Name – Указываем наименование создаваемого PD и кликаем Create;
- На закладке Entities мы вымираем список виртуальных машин, для которых мы включаем репликацию в рамках создаваемого домена защиты:
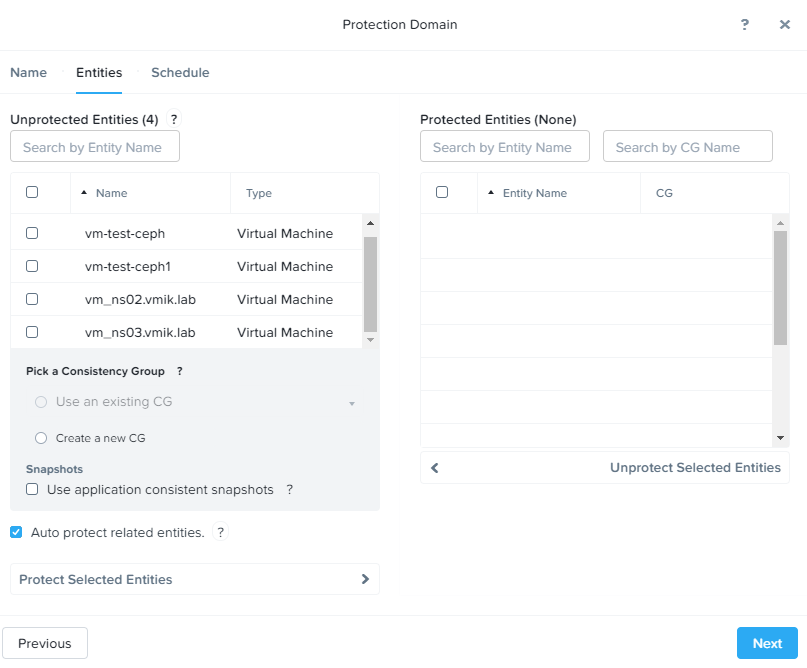
Unprotected Entities – виртуальные машины, которые не включены ни в один PD и которые мы можем защитить.
Protected Entities – виртуальные машины, которые уже включены в план репликации.
Use application consistent snapshots – использование VSS, pre-freeze/post-thraw скриптов в виртуальной машине. В виртуальных машинах должен присутствовать и работать NGT. Важный момент – при включенном параметре application consistent snapshots в Consistency Group может быть включена только одна VM:
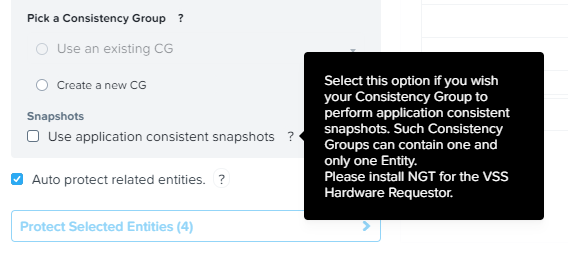
Выделяем требуемые для защиты VM и кликаем Protect selected entities. Виртуальные машины перемещаются в правую часть. Также для каждой VM создается свои Consistency Group.
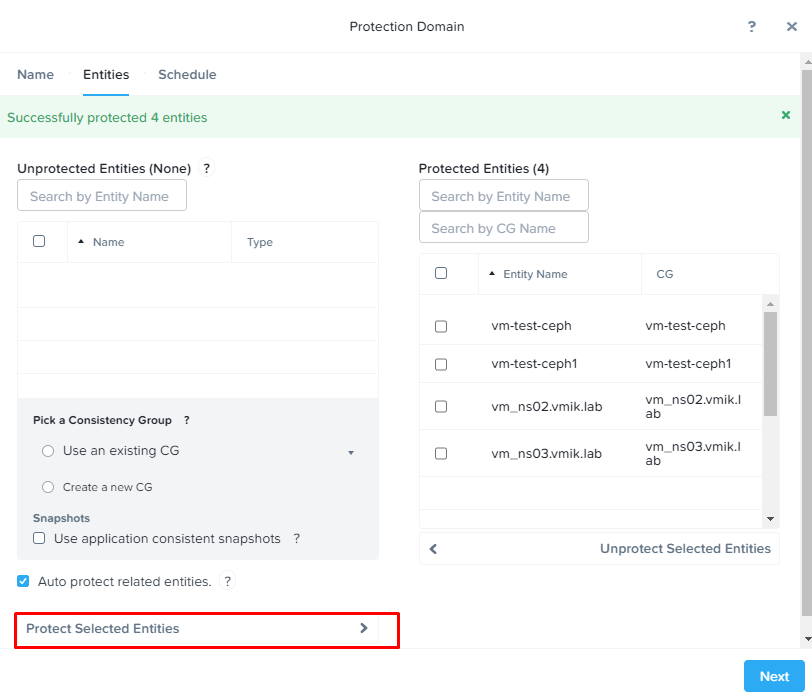
3. Выбрав машины для защиты, переходим на вкладку Schedule, где настроим расписание запуска процедуры репликации. Сделать это можно нажатием кнопки «New Schedule»:
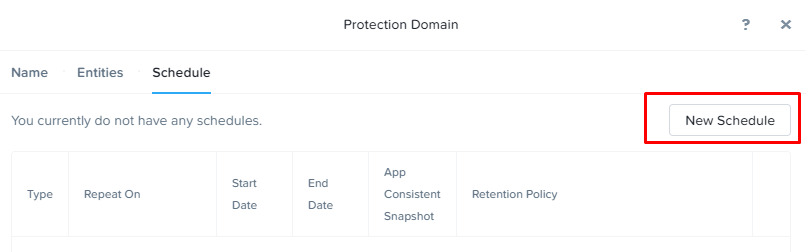
Здесь все крайне просто. Указывается частота запуска задачи, место, где мы будем хранить снимки (локальный, либо резервный кластер), а также количество хранящихся снимков.

Поскольку мы используем асинхронную репликацию и минимально возможное RPO у нас составляет один час, моя задача, согласно планировщика будет запускаться каждые 60 минут.
Все изменения в VM каждые 60 минут будут отправляться в кластер ntnx-ce-dr.vmik.lab, где будет храниться 24 последних снимка (т.е. минимальный PRO у нас составляет 60 минут, максимальный – 24 часа).
Нажимаем Create Schedule и готово. Расписание для Protection Domain создано.

Теперь на закладке Async DR отображается наш созданный PD:

Из интересного здесь можно увидеть количество VM/VG, которые включены в PD, дату и время следующего запуска, текущую скорость, на которой происходит загрузка данных.
Так же Protection Domain будет создан автоматически на резервном кластере:

Если кликнуть на PD основного сайта, можно будет увидеть несколько интересных вкладок:

- Replications – Отображает статус текущего процесса репликации, а также историю предыдущих запусков;
- Entities – Список виртуальных машин, относящихся к данной задаче репликации;
- Schedules – Расписание запуска задачи;
- Local Snapshots – Локальные снимки виртуальных машин. При необходимости, из них можно произвести восстановление VM в существующем кластере;
- Remote Snapshots – А это уже наши реплики на резервном кластере. Если кликнуть по снимку и выбрать «Details» в правой части, можно будет увидеть список VM, которые к данному снимку относятся;
- Metrics – Графики скорости приема\передачи реплик. На основном сайте у нас – передача, на резервном – прием;
- Alerts – Возникающие в процессе репликации ошибки;
- Events – События. Все взаимодействия с PD, запуски и прочее фиксируется здесь.
Шаг шестой. Наблюдать за процессом репликации:
К моменту, когда я дописал блок текста выше, у меня уже успешно прошла репликация четырех машин, поскольку все они имеют крайне малый размер.
Но всегда нужно помнить, что чем больше изначальный размер машин – тем дольше будет процесс выполнения первой репликации. Также на объем снимков и, соответственно, время репликации этих снимков в сторонний кластер влияет количество изменяемых данных в машине в промежуток между созданием снимков. Про это не нужно забывать.
На закладке Remote Snapshots отображается первый снимок:

А в Details можно увидеть виртуальные машины:
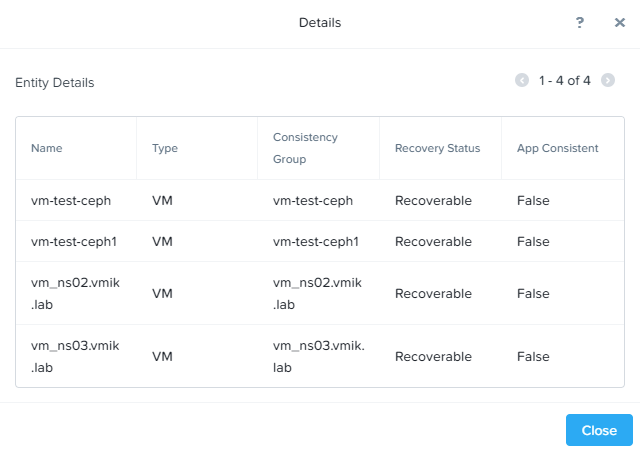
Аналогичным образом, все реплики можно просмотреть и на резервном кластере.
На текущий момент мы успешно настроили взаимодействие между двумя кластерами, создали правила репликации, а также настроили расписание, по которому данные реплики будут создаваться на резервном кластере.
В следующей части мы посмотрим детально на процесс восстановления виртуальных машин из созданных реплик.
![]()