Ранее я уже писал про репликацию виртуальных машин в vCloud Director с помощью Veeam Cloud Connect, однако результаты поисковых запросов, по которым приходят на данный сайт говорят, что осветить вопросы классической репликации тоже стоит.
Далее мы посмотрим на процедуру репликации виртуальных машин VMware с помощью Veeam от настройки задачи до переключения на резервную площадку и обратно.
Для незнакомых с таким понятием, как репликация: Репликация – это создание копии виртуальной машины, обычно, на другой площадке или в другом кластере с целью ее быстрого восстановления в случае сбоя виртуальной машины, либо площадки целиком.
При первом запуске процедура репликации полностью копирует виртуальную машину на удаленную площадку, а при последующих копируются только изменения.
Репликация предназначена для уменьшения времени восстановления виртуальной машины после сбоя (RTO). Например, произошел сбой на площадке, виртуальные машины были повреждены и не работают. В случае с классическим резервным копированием, необходимо будет сперва восстановить виртуальную машину из последней доступной копии, а затем ее запустить. На это может уйти значительное время, напрямую зависящее от объема машины. А если таких машин несколько?
В случае с репликацией нам достаточно просто включить копию машины (реплику), после чего система будет доступна, а данные в ней будут актуальны на момент последнего запуска операций репликации. Данная операция называется Failover.
Почему же всегда не использовать реплику вместо привычных бэкапов? Самая очевидная причина, что в большинстве случаев реплика – это наиболее актуальная копия защищаемой виртуальной машины и реплицироваться могут не только хорошие данные, но и плохие. Например, репликация делается каждые 30 минут, а несколько часов назад на машине завелся шифровальщик. Конечно, на этот случай имеется возможность откатиться на более раннюю реплику, если это настроено, но все же забывать про резервные копии не нужно.
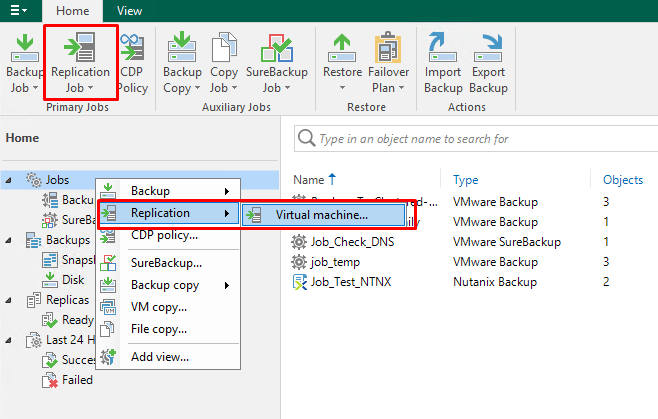
Создание задачи репликации:
Начинается все с создания задачи репликации по аналогии с любой другой задачей:
Нас сразу же встречает ряд настроек, влияющий на дальнейшие шаги:
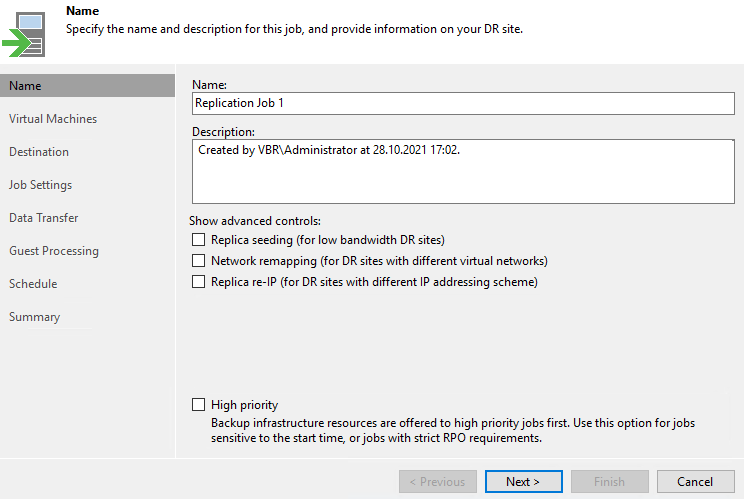
Replica seeding – чтобы не выполнять полную репликацию по сети, можно использовать резервные копии, которые располагаются на той же площадке, где планируется разместить реплику. В таком случае VM будет развернута из резервной копии, а после этого будут синхронизированы изменения;
Network remapping – если название сети на удаленной площадке к которой нужно подключить реплику отличается от сети на основной площадке, это нужно учесть;
Replica re-IP – если имеется необходимость в изменении IP адреса на удаленной площадке, так же отмечаем.
Изначально все галки не отмечены, что означает то, что виртуальная машина будет реплицирована как есть. В данном случае менять настройки сети я не планирую. На удаленной площадке доступны все те же сети.
Следующим шагом, по аналогии с задачами резервного копирования, выбираем виртуальные машины, для которых планируется создать реплику:
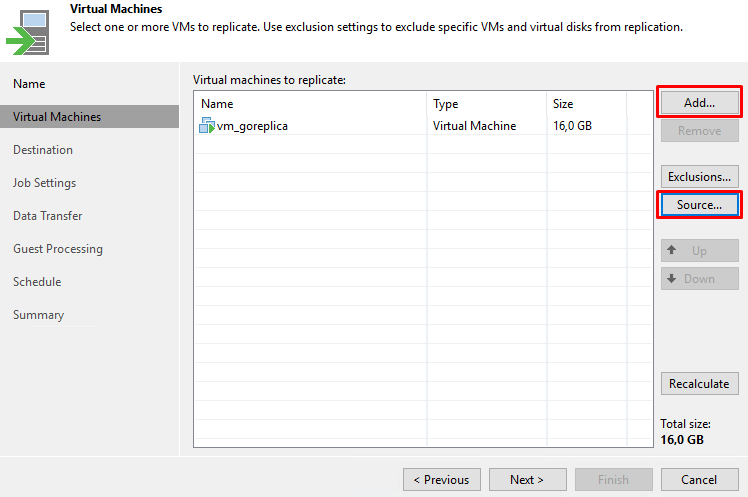
Сделать это можно через кнопку Add.
Здесь есть еще один интересный момент, а именно Source. Мы можем выбрать источник, из которого будут создаваться реплики виртуальных машин. Это могут быть оригинальные виртуальные машины, либо созданные ранее файлы резервных копий:

В первом случае, при запуске задачи репликации, будет производиться чтение с продуктивной VM, во втором случае с файла резервной копии.
Оба метода обладают как плюсами, так и минусами. Чтение с продуктивной VM может сказаться на ее производительности, но при этом реплика будет являться актуальной виртуальной машиной на момент запуска задачи.
При использовании существующих резервных копий в качестве источника для реплики, копия виртуальной машины будет аналогична состоянию виртуальной машины на момент создания резервной копии. В любом случае, следует отталкиваться от показателей RPO (Recovery Point Objective). Для частых копий, скорее всего, проще будет сделать реплику с продуктивной VM, а если копировать нужно редко, можно использовать резервные копии.
Например, резервная копия создается четыре раза в день. После задачи резервного копирования сразу же запускается репликация виртуальной машины из этой копии на удаленную площадку.
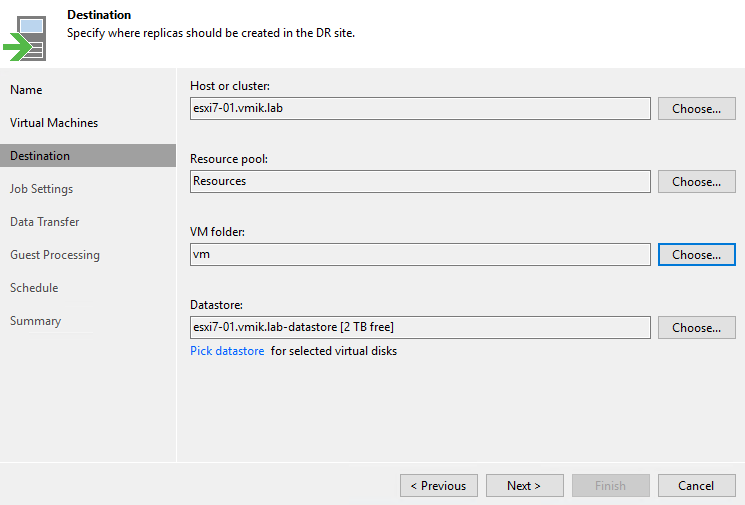
Следующим этапом мы выбираем место, где будут располагаться реплики. Это может быть другой хост, другой кластер, другой vCenter Server и т.п.
Очевидно, что хранить реплики в том же кластере и на том же хранилище не стоит.
В моем случае, в качестве удаленной площадки я выбираю другой vCenter Server и доступный там хост:
В пункте Job Settings указывается репозиторий, на котором будут располагаться метаданные реплики, количество точек восстановления для реплик, а также суффикс, который будет добавлен к названиям машин, которые являются репликами:

Каждая точка восстановления для реплики по своей сути является снапшотом виртуальной машины, а не отдельной виртуальной машиной.
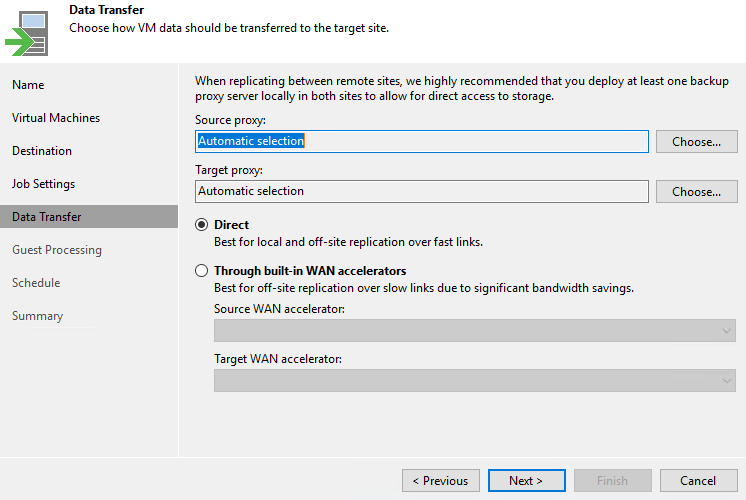
Следующим этапом указываются (либо не указываются) прокси, которые будут использованы для задач репликации. При необходимости можно задействовать WAN акселераторы:
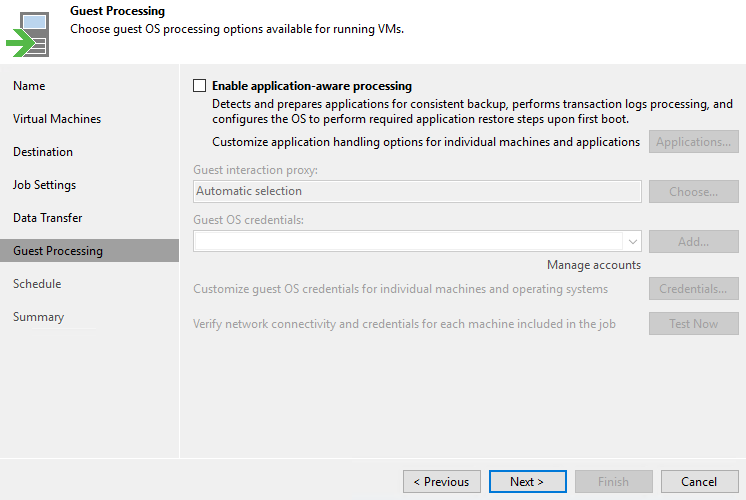
Guest Processing – подготовка виртуальной машины к репликации. То же самое, что и при настройке резервного копирования:
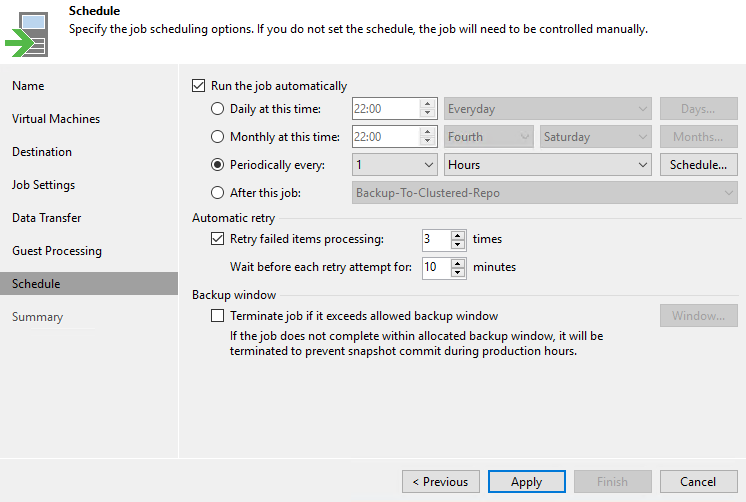
Последний пункт Schedule позволяет выставить расписание, по которому будет запускаться задача репликации. Здесь все зависит от требуемого значения RPO – он же промежуток времени, за который мы можем потерять данные.
Я планирую запускать задачу каждый час:
Клик по Apply и задача репликации создана:
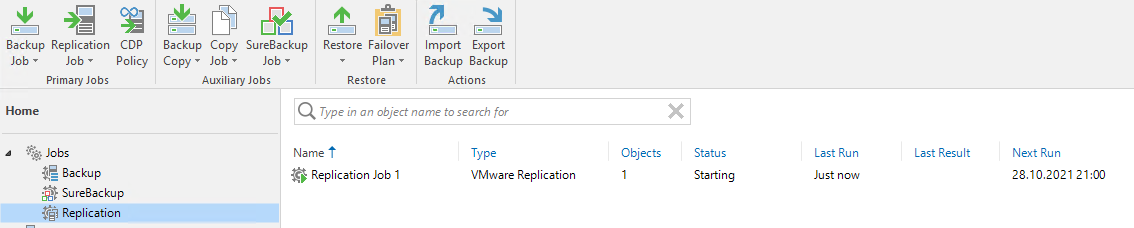
В моем случае совпало «минута в минуту» и задача автоматически запустилась. Посмотрим, что происходит в этот момент:
С оригинальной машины создается снапшот:
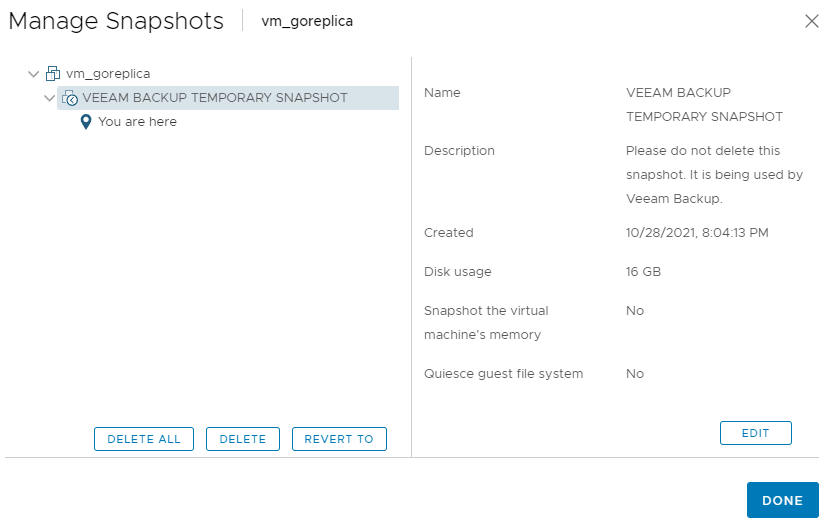
И начинается копирование на удаленную площадку:
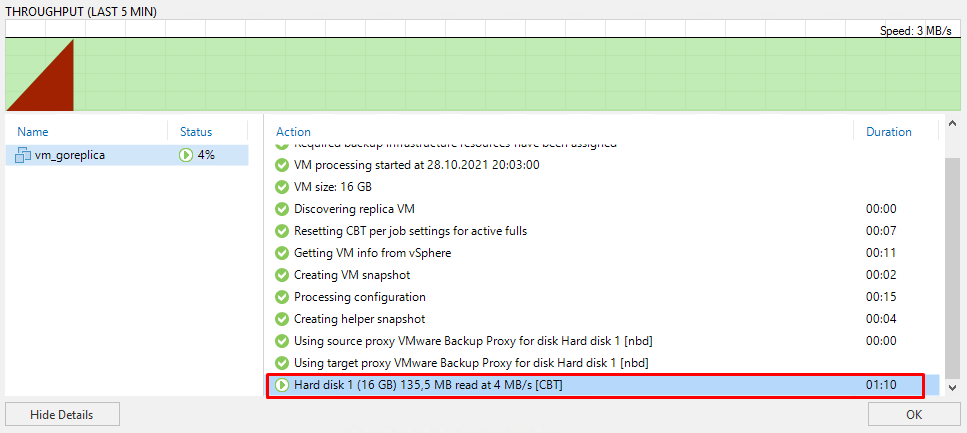
На удаленной площадке тем временем появляется виртуальная машина с соответствующим суффиксом _replica:
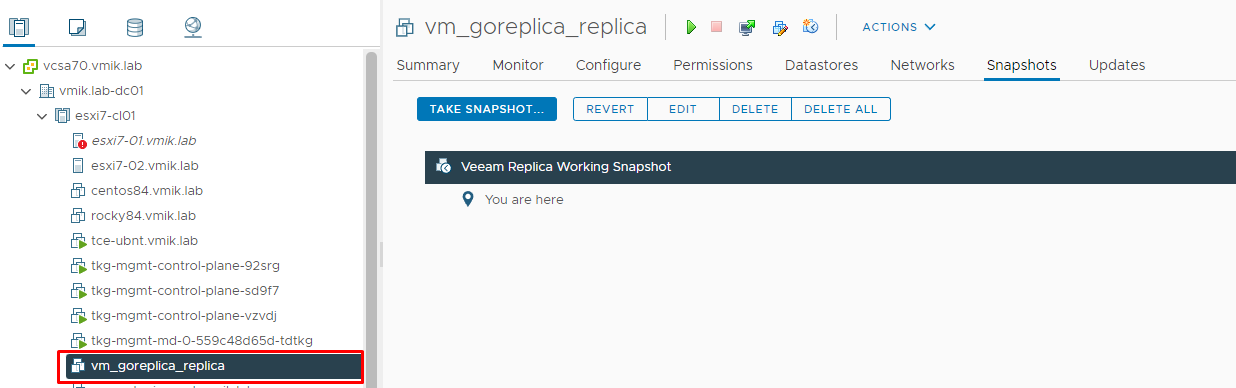
Обратите внимание на название снапшота – «Working Snapshot». После завершения реплики, название становится более говорящим:
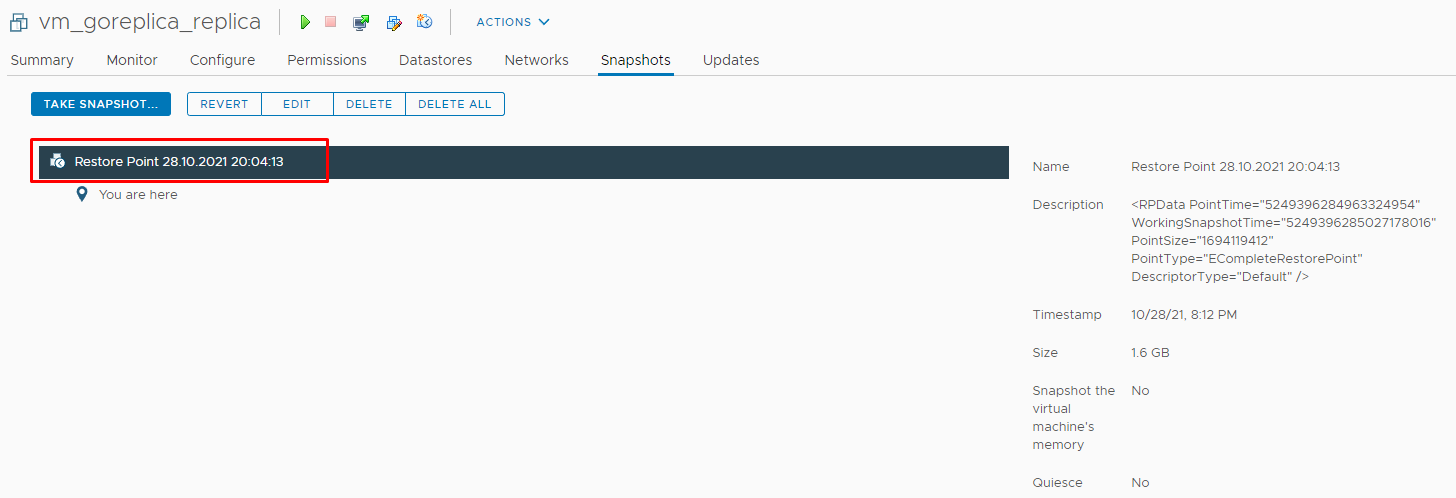
Теперь в консоли Veeam появляется новый пункт – Replicas:
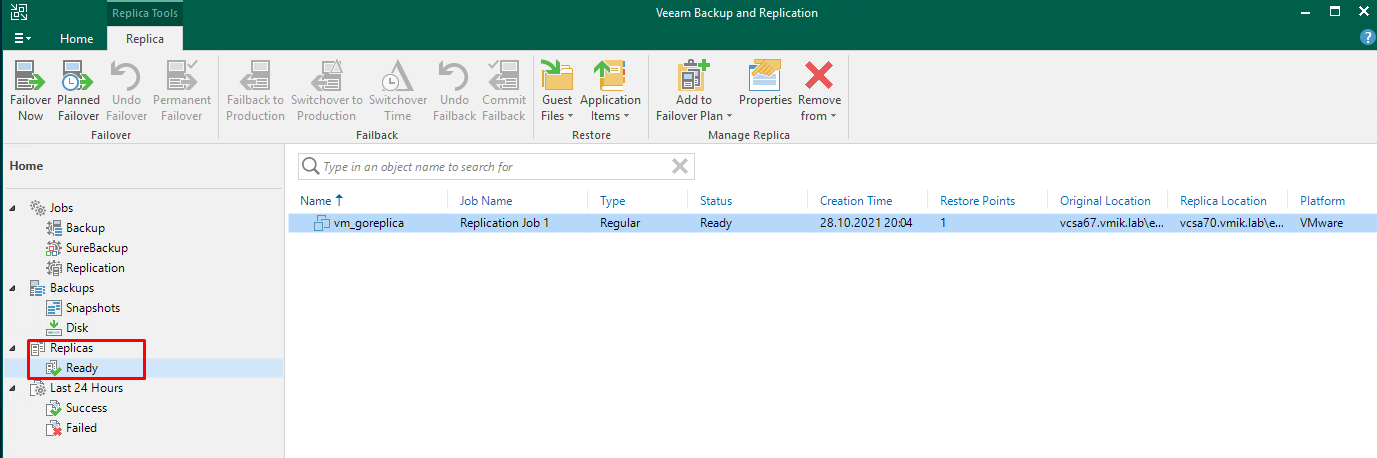
Здесь мы можем увидеть все виртуальные машины, для которых имеются реплики, их статус, количество точек восстановления.
Интересные поля – Original Location и Replica Location. Первое – где работает основная VM, а второе – где находится ее копия, как не сложно догадаться.
Спустя некоторое время, у виртуальной машины, которая является репликой, формируется целая цепочка снапшотов:
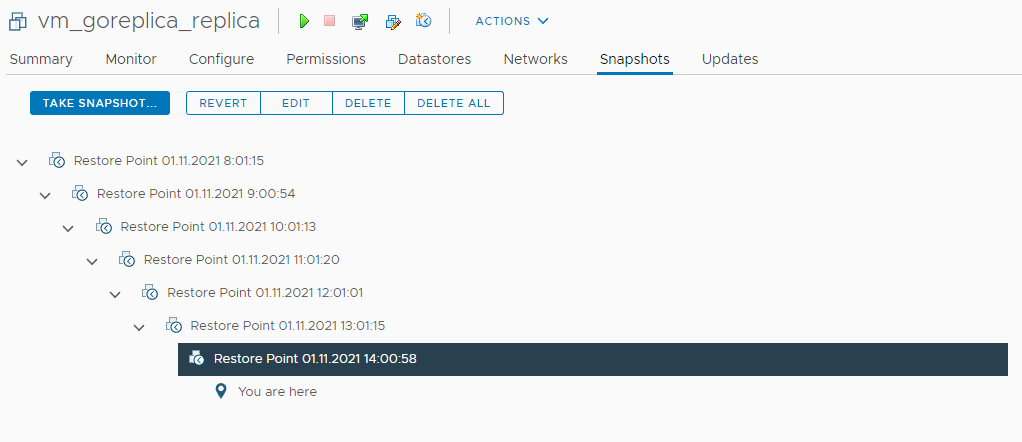
Всего их 7, согласно выставленным ранее настройкам.
Переключение на реплику:
С процедурой настройки задачи репликации мы разобрались. Теперь необходимо понять, как использовать реплики?
Если кликнуть на реплику правой кнопкой, мы увидим два варианта:
- Failover now;
- Planned failover.
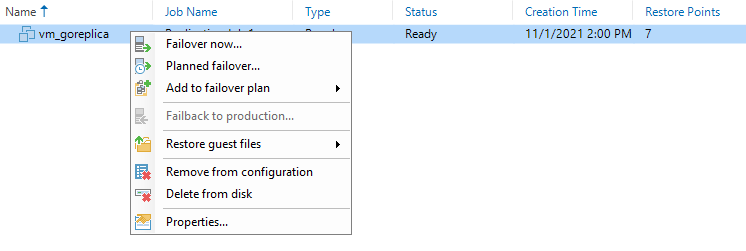
Между двумя вариантами есть принципиальная разница. Посмотрим, как работает каждый из них:
Failover now:
- Включает реплику на удаленной площадке из выбранной доступной точки восстановления.
Все просто, но есть один момент, если основная машина работает, а в этот момент будет запущена процедура Failover, вы получите две одновременно работающие машины, возможно, даже с одинаковыми IP адресами, что не очень хорошо.
Planned failover:
- Незамедлительно выполняет репликацию актуальных данных на удаленную площадку;
- Выключает оригинальную VM;
- Повторно выполняет репликацию, т.е. данных которые успели сгенерироваться с момента предыдущей реплики и до выключения VM;
- Включает реплику на удаленной площадке.
Данный метод позволяет синхронизировать все изменения между основной VM и ее репликой, после чего запускает реплику. В момент между финальной синхронизацией и запуском реплики, обе виртуальные машины не будут доступны, это следует учитывать.
Можно сделать выводы, что Failover now подходит в случаях, когда основная VM уже недоступна и нам необходимо запустить ее последнюю доступную копию с минимальными временными затратами, а Planned failover, как бы это не звучало, подходит для планового переключения нагрузок с основной на резервную площадку с полной предварительной синхронизацией данных.
Взглянем детальнее на работу Planned failover:
Мы видим, что последняя доступная точка восстановления у виртуальной машины 15:01:
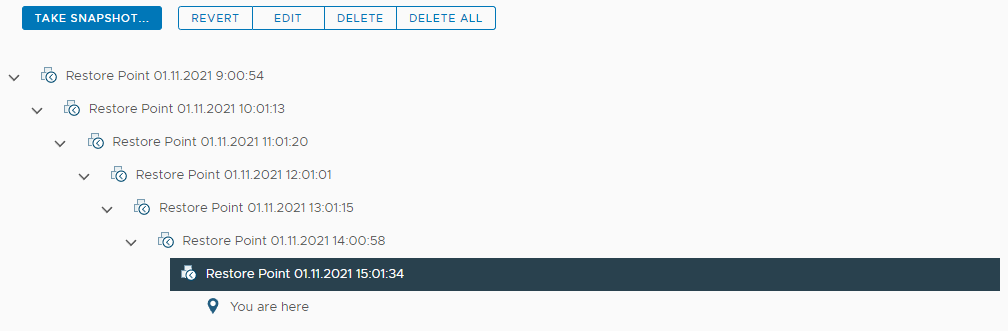
Внесем изменения в виртуальную машину:
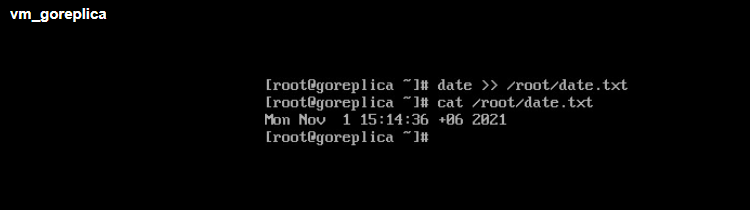
И запустим операцию Planned failover:
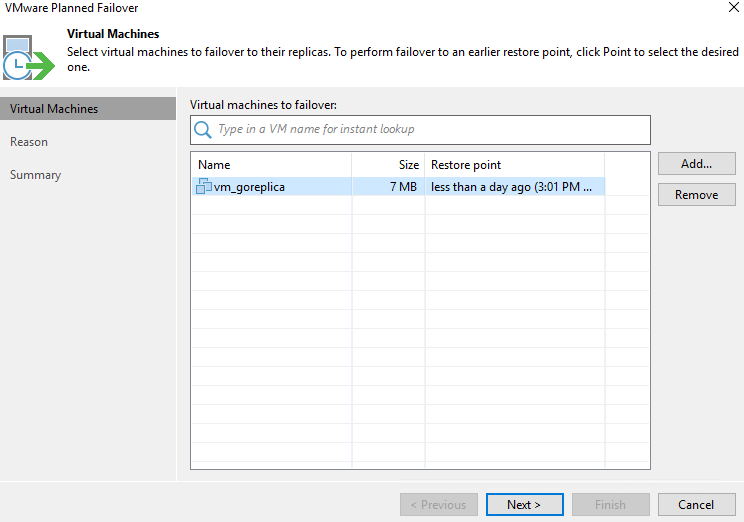
В данном случае мы не можем выбрать какую-либо точку восстановления, потому что синхронизироваться будут в любом случае актуальные данные.
Начинается первый этап синхронизации:
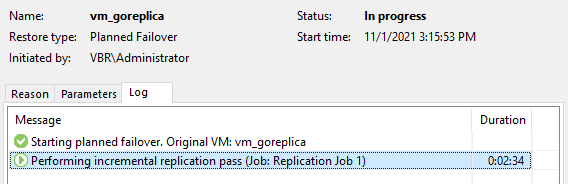
На реплицируемой машине появляется временный снапшот:

В момент выполнения данной операции основная машина находится в работе, а реплика выключена.
После выполнения первой синхронизации, выполняется отключение основной машины и последняя синхронизация в уже выключенном состоянии:
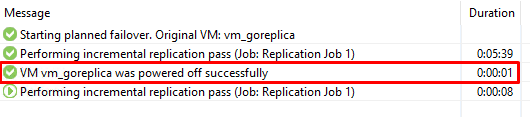
В данный момент у нас нет активных виртуальных машин и сервис не доступен. Нужно об этом помнить.
После двух операций синхронизации у нас появляется две новые точки восстановления:
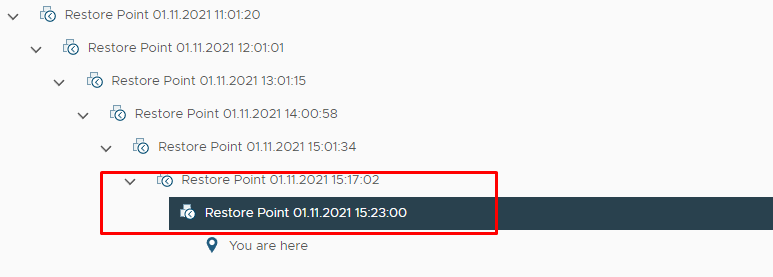
Более старые точки будут удалены и нужно иметь это ввиду.
По окончанию синхронизации, Veeam включает реплику и сообщает о том, что операция Failover выполнена успешно:
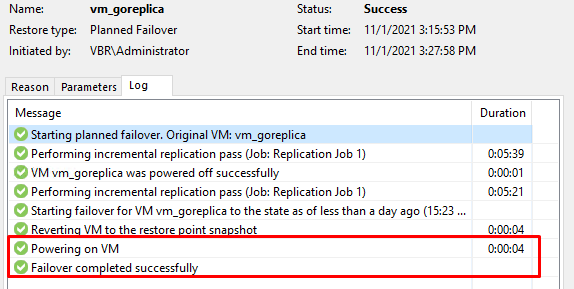
На текущий момент основная машина отключена, в то время, как реплика включена.
Подключившись к реплике убедимся, что внесенные изменения были реплицированы:
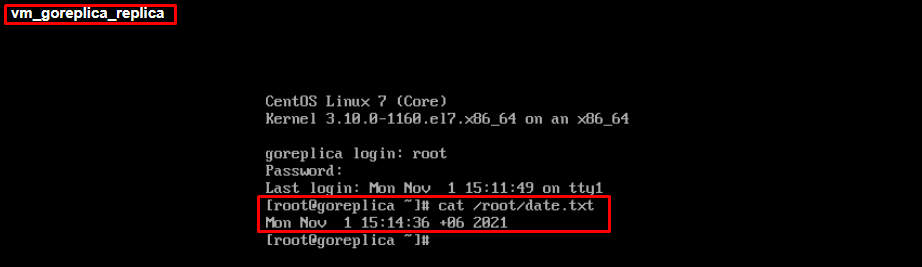
Согласно задачи репликации, последняя точка восстановления была сделана в 15:01, но наши изменения в 15:14 были реплицированы, а значит операция Planned failover отработала как ожидается.
Если сейчас вернуться в консоль Veeam мы можем увидеть, что у нас имеется одна активная в настоящий момент реплика:
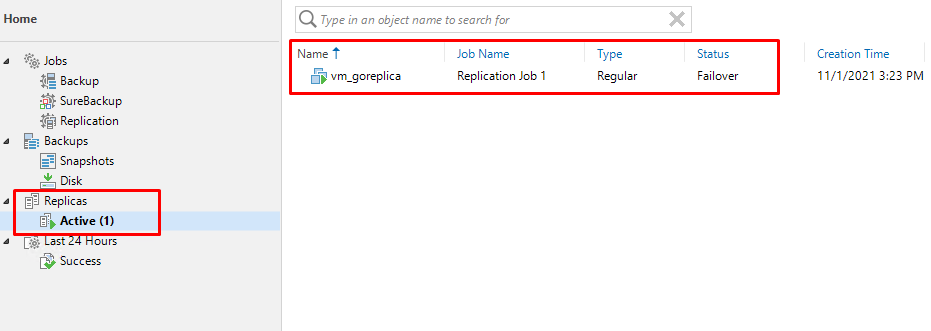
Лирическое отступление: один из поисковых запросов, который привел на мой сайт читателя, звучал следующим образом «Veeam репликация во время операции failover».
Не берусь утверждать, что именно имелось ввиду, но скорее всего – можно ли реплицировать данные с основной на резервную площадку, когда Failover уже активен? В первую очередь стоит спросить себя: зачем это делать? Если в настоящий момент активна реплика, значит наиболее актуальные данные находятся скорее всего там и реплицировать с основной на резервную площадку смысла нет в принципе.
Но ответ на данный вопрос такой: если запустить задачу репликации для машины, которая находится в состоянии Failover, то мы получим ошибку: Error: Cannot process the VM because the target VM state is failover. Что говорит нам о том, что сделать реплику для машины, которая находится в состоянии failover нельзя (что логично).
Возврат на основную площадку:
Теперь вернемся назад к нашей реплике. Включив виртуальную машину на резервной площадке возникает вопрос – как переключаться обратно? Для просмотра возможных вариантов, кликнем правой кнопкой на активную реплику в консоли Veeam:
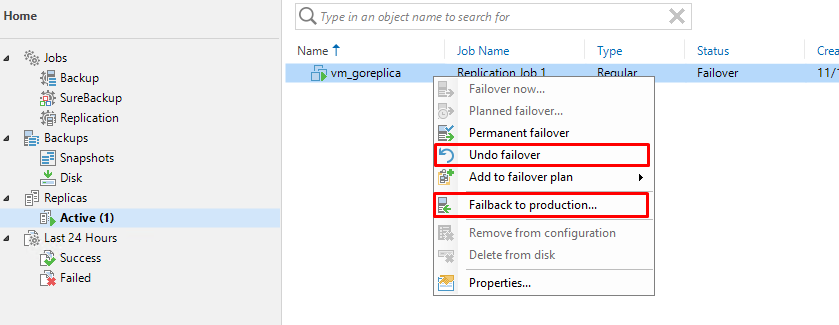
Здесь есть две отличные друг от друга опции. Undo failover и Failback to production.
Undo failover – отменяет все внесенные с момента переключения изменения и отключает реплику.
Failback to production – синхронизирует изменения сделанные в реплике с виртуальной машиной на основной площадке, после чего выполняет переключение обратно.
Допустим, на момент выполнения плановых работ, мы выполнили переключение на резервную площадку, после чего внесли там какие-то изменения и хотим переключиться обратно.
Внесем изменения в работу виртуальной машины на удаленной площадке:
Теперь выбираем пункт Failback to production в консоли Veeam:
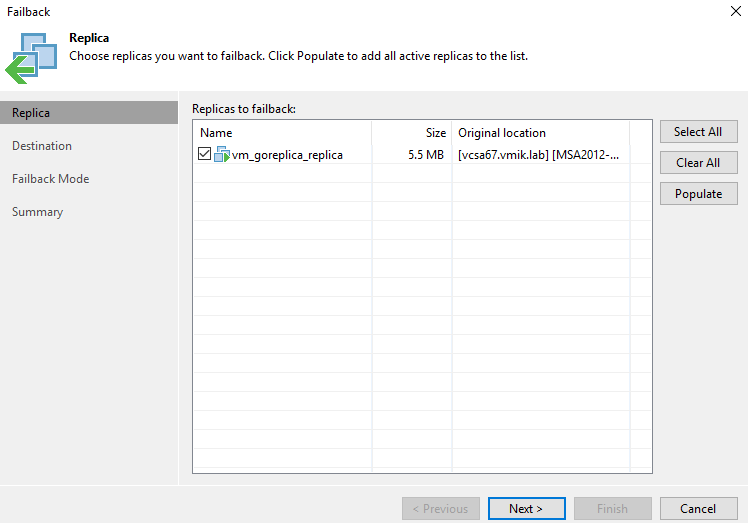
В пункте Destination мы можем выбрать – синхронизировать изменения с оригинальной VM, с VM, которая была восстановлена из резервной копии, либо вообще развернуть новую виртуальную машину из реплики:
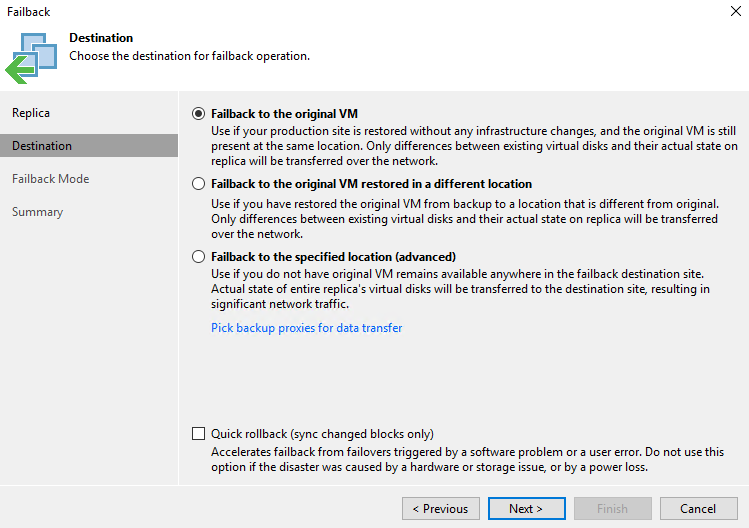
Первый вариант больше подходит при плановом переключении, а вторые два, если ранее мы потеряли виртуальные машины на основной площадке.
Я оставляю первый вариант и синхронизирую изменения с оригинальной виртуальной машиной.
Failback mode – интересная опция, которая позволяет выполнить переключение либо автоматически, либо в определенное время, или же по команде администратора:
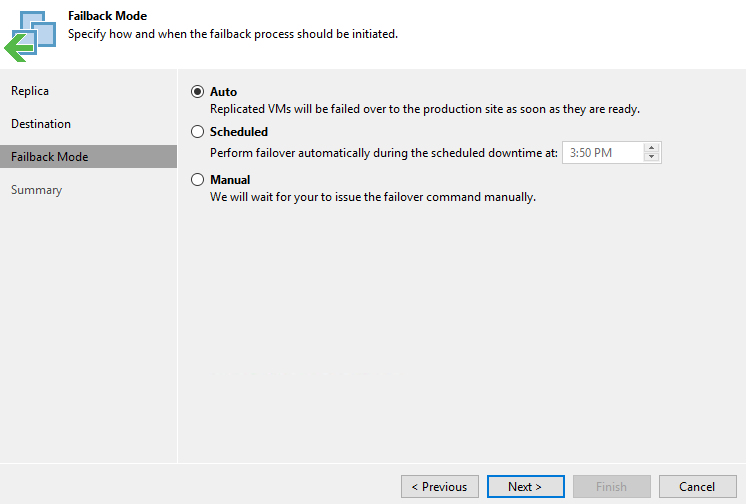
Для проверки я выбираю режим Manual. Следующим шагом Veeam заботливо предупреждает, что в момент операции failback реплика будет отключена. Запускаем нажатием Finish:
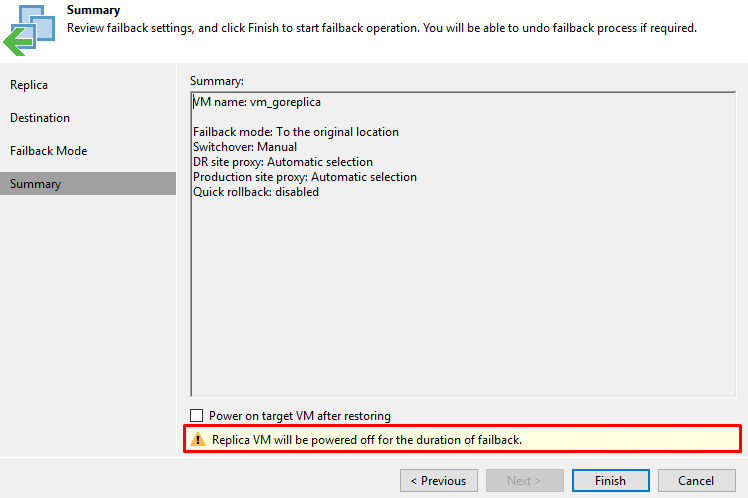
На момент запуска операции Failback, запущена реплика, а оригинальная VM находится в выключенном состоянии.
На основной машине создается временный снапшот:
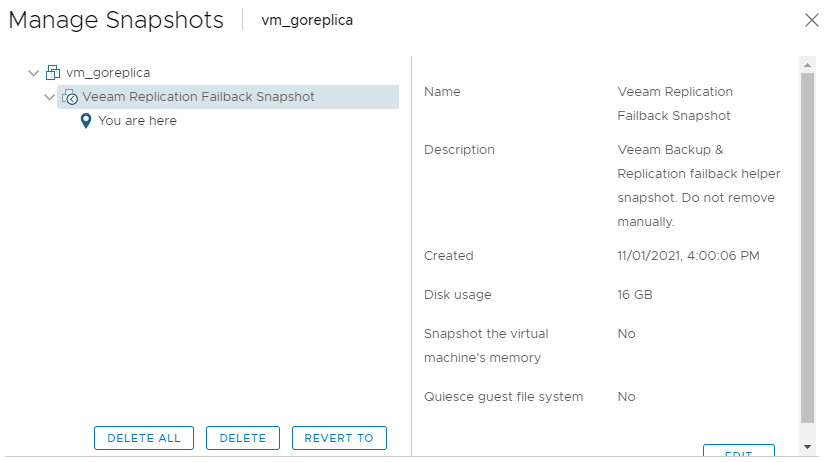
Аналогичным образом снапшот создается и на реплике.
Далее Veeam проводит анализ дисков реплики и основной системы для определения данных, которые необходимо перенести с реплики на основную систему:

После чего начинается репликация изменений уже с реплики на основную машину:

По окончанию синхронизации мы получаем сообщение о том, что переключение будет выполнено вручную, как и указывалось ранее:

На текущий момент реплика продолжает работу, в то время как оригинальная виртуальная машина еще не запущена. Клик правой кнопкой по реплике и выбор пункта меню «Switchover to production» запустит процедуру переключения:
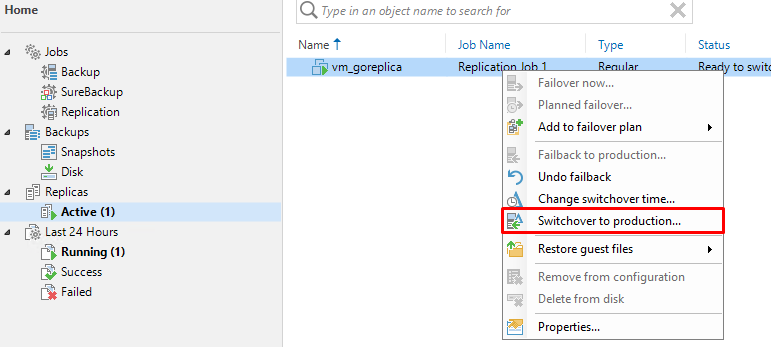
Дальше происходит следующее:
- Реплика отключается;
- Выполняется синхронизация с реплики на основную VM;
- Основная VM включается.
По логу задачи видно, что произошло отключение реплики и финальная синхронизация:
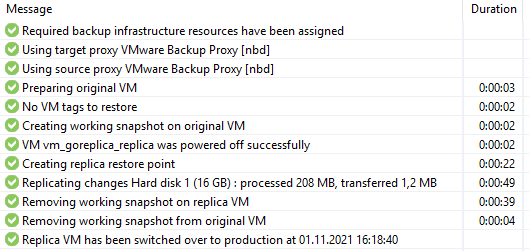
Синхронизация данных завершилась. Основная машина находится в выключенном состоянии, как и реплика.
Включим, проверим:
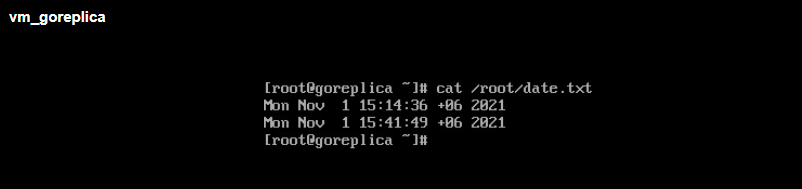
Внесенные перед операцией Failback изменения перенеслись корректно на основную площадку.
Но и это еще не все. Если обратить внимание в консоль Veeam, можно увидеть, что операция репликации все еще активна. Нам доступно две новые опции – Commit failback и Undo failback:
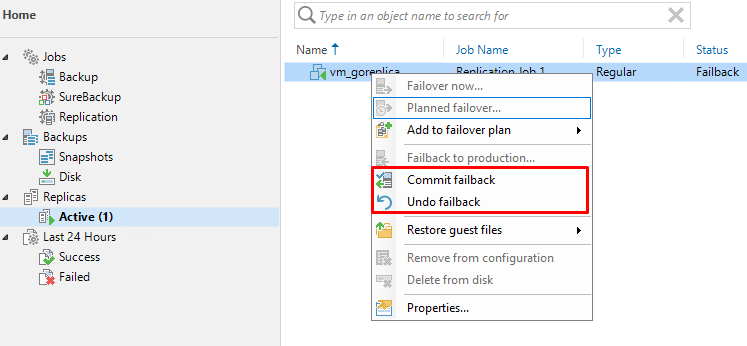
Commit failback – подтверждаем, что переключение произошло успешно, виртуальная машина на основной площадке работает. Завершаем операцию Failback;
Undo failback – если по какой-то причине машина на основной площадке отказывается работать, отменяем операцию failback и включаем реплику обратно.
В моем случае все прошло успешно, поэтому я завершаю операцию Failback с помощью Commit:
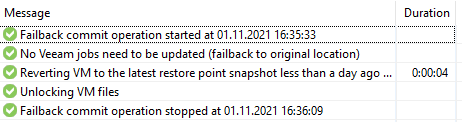
Через несколько минут, уже по расписанию вновь запускается операция репликации с основной площадки на резервную:

Следует учесть, что после операций Failover/Failback может возникнуть проблема с CBT (change block tracking) и первая инициализация реплики будет идти дольше, как на скриншоте выше.
На этом мы полностью рассмотрели процедуру создания задач репликации в Veeam, а также плановое переключение на реплику и возврат обратно.
Итоги:
Процедура настройки репликации достаточно проста. Нам необходимо указать источник данных для реплики – из резервной копии, либо напрямую из VM, место, где будут располагаться реплики, обычно это другой дата центр или хоти бы другой кластер, а также периодичность запуска задач в зависимости от требуемых значений RPO.
В случае аварийной ситуации, когда основная площадка недоступна, мы можем использовать Failover now чтобы включить виртуальные машины из реплик на резервной площадке. Если же мы планируем плановое переключение, следует использовать Planned failover.
Failover now включает последнюю актуальную копию реплики (либо можно указать конкретную доступную точку), в то время как Planned failover синхронизирует все изменения между основной машиной и репликой, после чего отключает основную машину и включает реплику, выполнив при этом финальную синхронизацию.
После переключения на реплику мы можем либо остановить операцию с помощью Undo failover, либо синхронизировать сделанные на резервной площадке изменения на основную площадку с помощью Failback to production.
Далее мы должны убедиться, что переключение на основную площадку прошло успешно и подтвердить его с помощью Commit failback, или же отменить, выполнив Undo failback.
В качестве заключения:
Несмотря на то, что настройка репликации, да и сама процедура ее работы достаточно просты, есть несколько моментов над которыми стоит подумать и все они больше организационные:
- Как часто делать репликацию от чего будем отталкиваться при принятии решения?;
- Что возьмем за источник? Резервную копию? Или продуктивную машину?;
- Куда делать репликацию? В соседний кластер или в другой дата центр и почему? А что с сетями?;
- Где будем размещать управляющий сервер Veeam? На основной площадке или на резервной?;
- В каком порядке будет запускать виртуальные машины в случае сбоя? Можно ли эту процедуру упростить (подсказка: Failover Plan);
- Как будем проверять реплики на работоспособность?.
Над всеми этими вопросами советую подумать самостоятельно на досуге 🙂
![]()