В первой части мы познакомились с процедурой настройки асинхронной репликации виртуальных машин между двумя кластерами Nutanix.
Сегодня мы посмотрим на процедуру как планового запуска виртуальных машин на резервном кластере, так и на запуск виртуальных машин на удаленной площадке, в случае возникновения проблем на основной.
Стоит вспомнить, что в прошлый раз мы успешно настроили связь двух кластеров между собой, а также запустили ежечасную процедуру репликации виртуальных машин из кластера ntnx-ce.vmik.lab в кластер ntnx-ce-dr.vmik.lab.
На текущий момент на резервном кластере находится 24 точки восстановления:
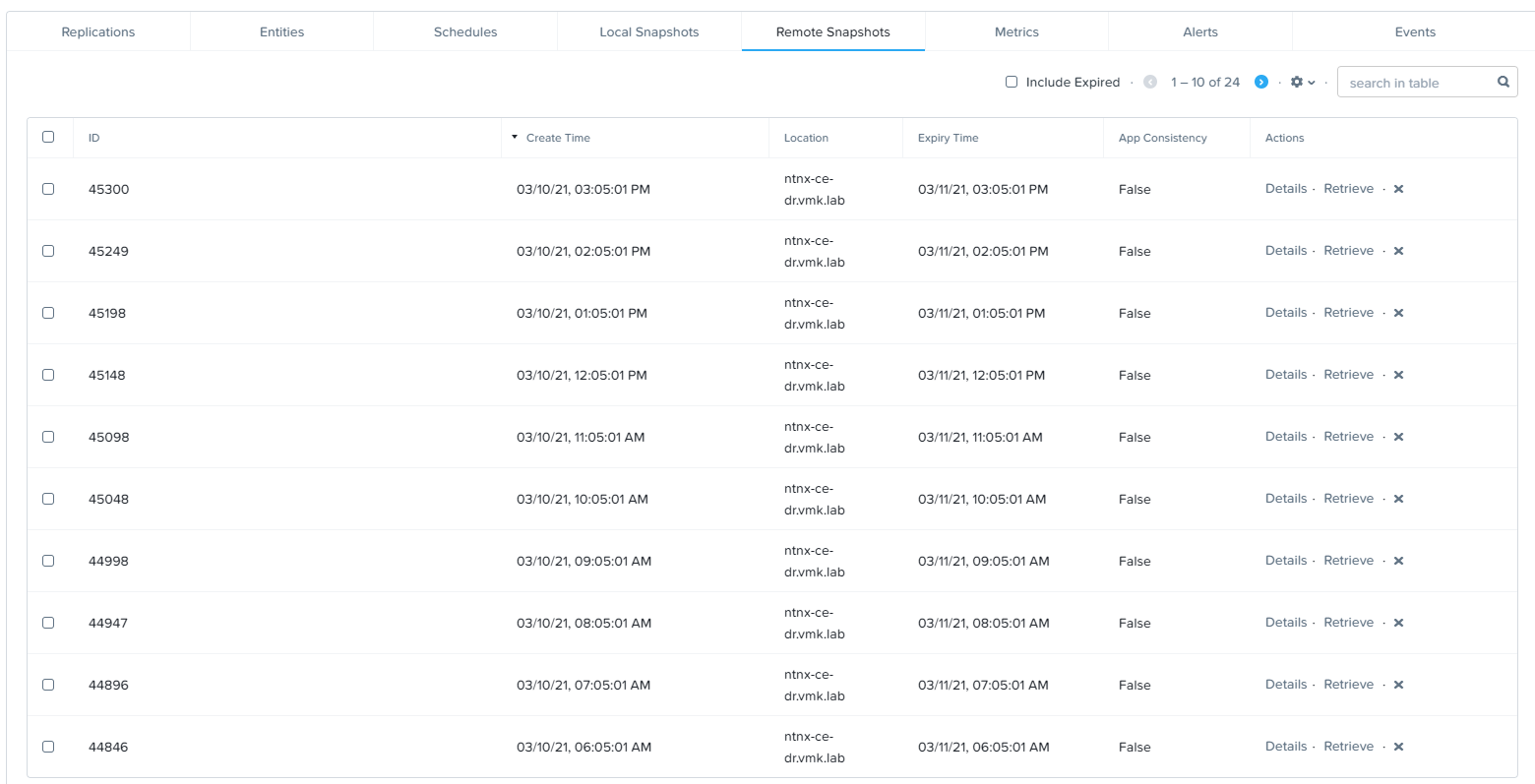
Репликация выполняется раз в час, что является минимально допустимым временем для асинхронной репликации. В случае необходимости других показателей RPO, следует обратить внимание на NearSync репликацию.
Перейдем к практике.
Начнем с самого нетипичного случая – восстановление виртуальных машин на основном сайте из копий, лежащих на удаленной площадке.
Просто так восстановиться из снапшота с резервного кластера не получится. Для начала необходимо перенести данный снапшот на основную площадку с помощью соответствующей кнопки «Retrieve».
Переходим на закладку Data Protection, выбираем нужную задачу репликации и на закладке «Remote Snapshots» указываем требуемую точку восстановления, из которой необходимо восстановить машину. После чего кликаем на «Retrieve»:
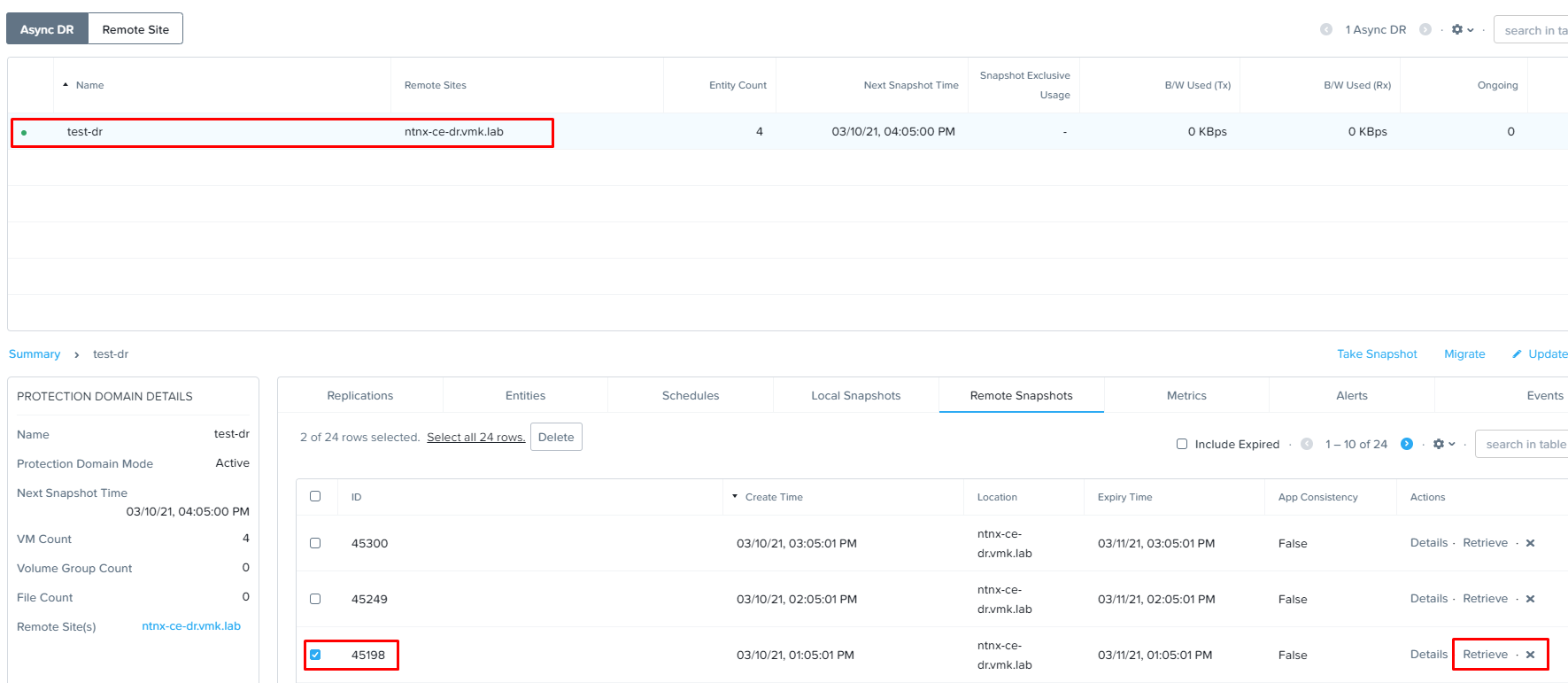
Нас спросят – действительно ли мы хотим запросить снапшот с удаленного кластера? – соглашаемся.
Переходим на закладку Local Snapshots и теперь здесь можно увидеть снапшот с ID, который был запрошен с резервного кластера:

В правой части можно увидеть кнопку «Restore», нажатие по которой запустит процедуру подготовки к восстановлению виртуальных машин:
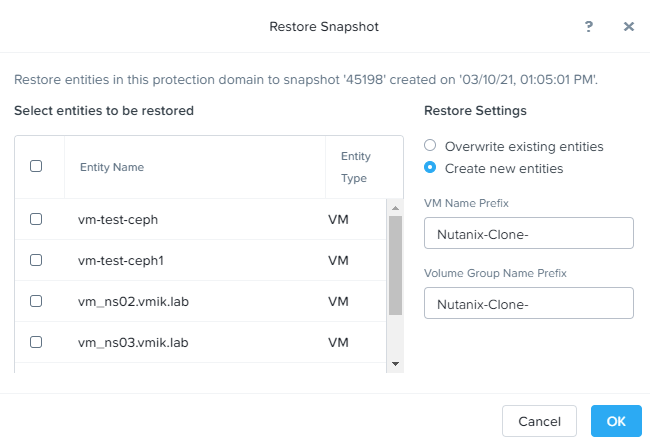
Здесь мы можем выбрать из списка виртуальные машины, которые планируется восстановить.
Мы можем либо перезаписать существующие машины (что, наверное, делать не стоит), либо создать новые машины, к которым будет добавлен соответствующий префикс, чтобы эти машины как-то отличались от уже существующих. По умолчанию это Nutanix-Clone-. Отмечаем VM, которые необходимо восстановить и, при желании, указываем отличный от оригинального префикс:

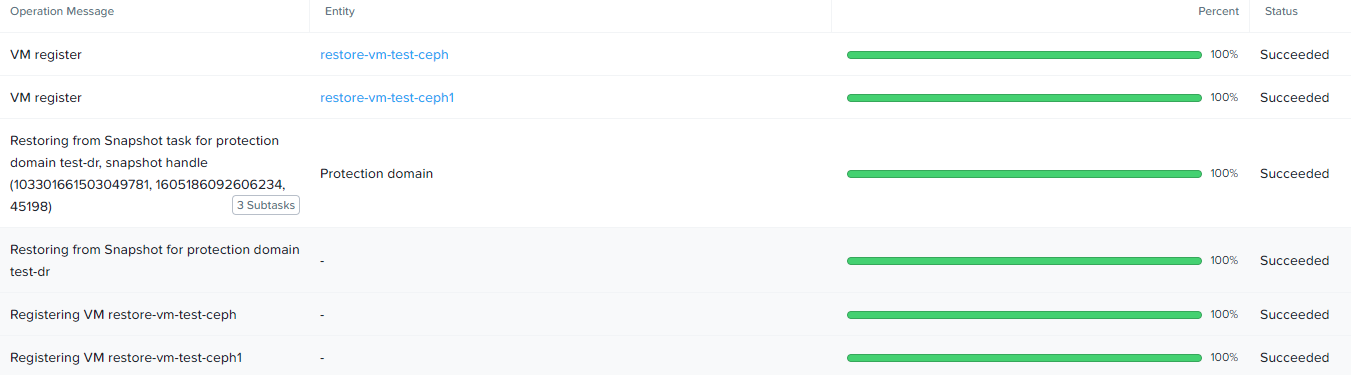
После чего, нажатие кнопки OK запустит процесс восстановления и будут созданы соответствующие задачи, статус которых можно просмотреть в журнале:
По окончанию восстановления, виртуальные машины появятся в общем списке. Включим и убедимся, что все работает:
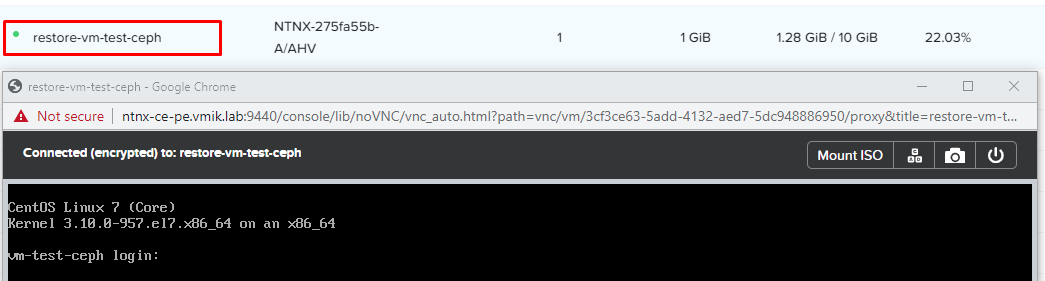
Вот так просто мы протестировали процедуру восстановления из снимков с резервной площадки.
Теперь перейдем к более интересному моменту – плановое переключение на резервную площадку.
Допустим, нас ожидают какие-то крайне длительные работы на основной площадке и столь длительный простой в работе систем мы позволить себе не можем, либо это могут быть работы для проверки того, что механизм Disaster Recovery функционирует корректно.
Для этого существует процедура плановой миграции Protection Domain (PD) на резервную площадку.
Процедура плановой миграции работает следующим образом:
- После активации планового переключения, для PD создается снапшот и переносится на резервную площадку;
- Следующим шагом все виртуальные машины, входящие в Protection Domain, отключаются (лучше, конечно, сделать это самостоятельно до начала процедуры миграции и корректно остановить все приложения и системы);
- Затем создается еще один снимок и переносится на резервную площадку;
- После переноса снапшота, виртуальные машины, а также Voulme Groups, относящиеся к переносимому PD исключаются из кластера, а все связанные с ними файлы удаляются;
- После этого, основная площадка помечается как неактивная;
- На резервной площадке восстанавливаются все виртуальные машины, сохраняя при этом оригинальные UUID;
- PD на резервной площадке становится активным.
Стоит отметить, что виртуальные машины на резервной площадке будут находиться в выключенном состоянии. Также, необходимо самостоятельно подключить VG к виртуальным машинам, которые были мигрированы.
Проверим на практике. Внесем некоторые изменения в одну из VM, входящих в Protection Domain test-dr:

Теперь перейдем в меню Data Protection, выберем PD, который мы планируем запустить на резервной площадке и кликнем «Migrate» в левой части экрана:
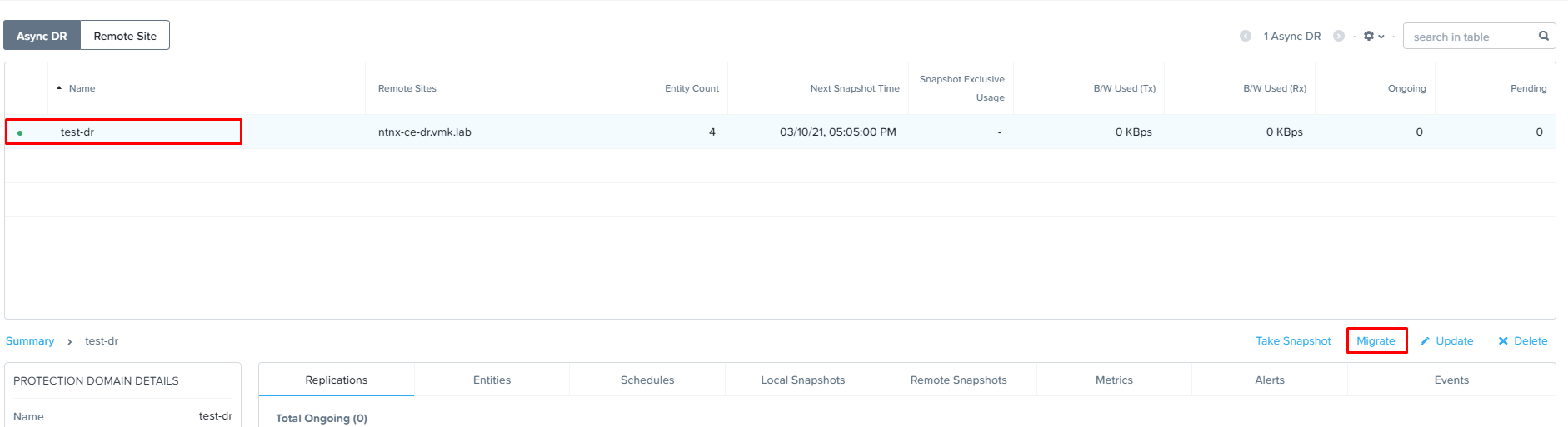
Система предложит выбрать кластер, на котором мы хотим запустить реплики наших виртуальных машин и попросит подтвердить начало миграции, вводом MIGRATE большими буквами в предназначенное для этого поле:

После подтверждения и нажатия кнопки Migrate, можно ожидать недоступность виртуальных машин.
Если наблюдать за списком выполняемых задач на основной площадке, можно будет увидеть шаги о которых говорилось ранее, а именно – две процедуры репликации, отключение и удаление существующих VM:

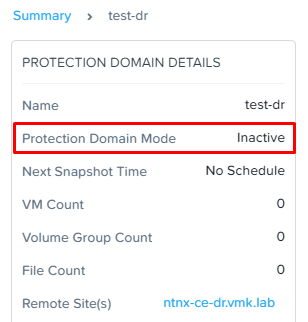
Protection Domain при этом ожидаемо неактивен на основной площадке:
Также основной площадке больше нет мигрированных VM (работает только одна машина, которая не относится к перемещаемому PD):
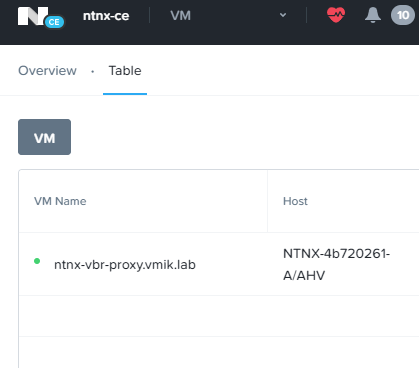
Переходим на резервную площадку.
На закладке Data Protection можно увидеть, что PD test-dr теперь активен здесь:
Если посмотреть в список задач, будет видно, что в кластере были зарегистрированы наши VM, а также был активирован Protection Domain:

Все виртуальные машины ожидаемо находятся в выключенном состоянии:
Запустим одну из них и проверим наличие внесенных ранее изменений:

Как можно заметить, последние изменения, сделанные перед переключением с основной площадки на резервную, были внесены.
Внесем изменения в виртуальную машину, запущенную на резервной площадке:

Теперь переключимся обратно на основную площадку. Делается это аналогично, только теперь с резервной площадки.
На закладке Data Protection резервной площадки выбираем PD и кликаем по кнопке «Migrate». Теперь в качестве целевого кластера мы указываем нашу основную площадку:

На резервной площадке также будут отключены машины, которые переносятся на основную площадку, будут скопированы изменения, после чего виртуальные машины будут удалены:

Все 4 виртуальные машины вновь на основной площадке:
Проверим внесенные в виртуальную машину vm-test-ceph изменения, сделанные непосредственно до запуска обратной процедуры миграции:
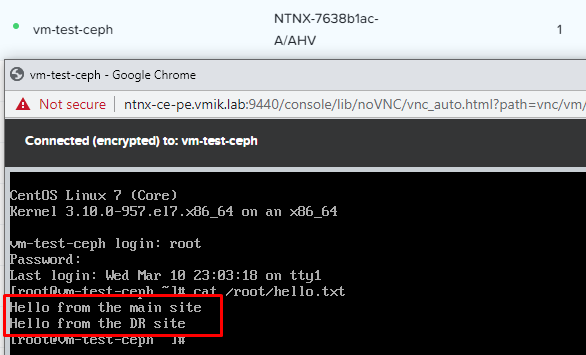
Все в порядке. Изменения корректно реплицированы.
Таким образом мы выполнили процедуру плановой миграции виртуальных машин с основной площадки на резервную и обратно. Как уже было отмечено, все изменения корректно переносятся в обоих случаях. Однако, напомню, что было бы неплохо до начала процедуры плановой миграции, самостоятельно отключить перемещаемые виртуальные машины и не перекладывать эту задачу на плечи системы виртуализации.
К данному моменту мы просмотрели два сценария – восстановление виртуальных машин из снимков, хранящихся на резервной площадке и плановую миграцию.
Третьим и, пожалуй, самым интересным является запуск виртуальных машин на резервной площадке, в случае выхода из строя основной.
Предположим, что из строя вышла основная площадка, на которой располагались виртуальные машины, но резервная площадка все еще доступна. Например, как у меня 🙂 :

Алгоритм действий в данном случае следующий:
- Подключаемся к резервной площадке и переходит в раздел Data Protection – Async DR;
- Выбираем Protection Domain, виртуальные машины которого требуется запустить на резервной площадке и кликаем Activate.
Данная операция зарегистрирует в кластере виртуальные машины из последнего доступного снапшота, при этом текущий PD станет активным.
Так же, как и при плановой миграции, виртуальные машины будут находиться в выключенном состоянии.
Проверим, как это работает. Переходим в раздел Data Protection – Async DR резервной площадки и активируем Protection Domain test-dr:
Система спросит – уверены ли мы в своих действиях и действительно хотим активировать PD. Да, уверены:
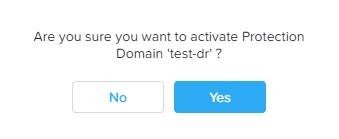
PD переходит в статус «активного», о чем сообщает наличие зеленого индикатора слева:
В журнале задач фигурируют сообщения аналогичные плановой миграции:

Виртуальные машины находятся ожидаемо в выключенном состоянии:
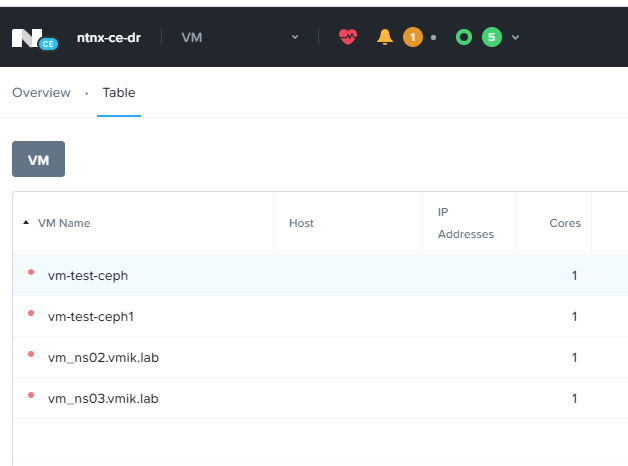
Включаем и восстанавливаем работоспособность систем уже на резервной площадке:
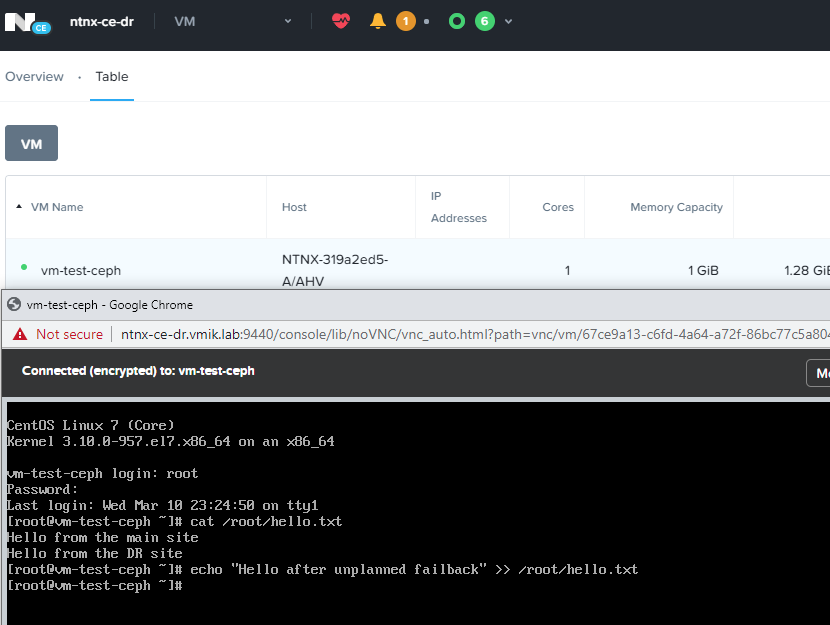
Итак, на данный момент у нас недоступна основная площадка и все системы запущены на резервной.
Может возникнуть резонный вопрос – что делать, когда основная площадка восстановлена и как вернуть виртуальные машины обратно?
Внимание: при выполнении нижеследующих операций, стоит быть крайне внимательным, ознакомиться с официальной документацией и, по возможности, проконсультироваться с технической поддержкой.
- После запуска всех хостов на основной площадке, CVM будут запущены автоматически. При этом, все PD на основной площадке, которые были активны до момента аварии, также будут находиться в активном состоянии. Складывается ситуация, при которой один и тот же PD активен и на основной и на резервной площадке (где в данный момент работают виртуальные машины);
- Поскольку оба PD находятся в активном состоянии, репликация между ними работать не будет;
- Далее необходимо подключиться к CVM на основной площадке (где VM в данный момент не работают) и активировать возможность запуска скрытых команд ncli:
$ ncli -h true
- После чего деактивировать существующий активный PD на основной, только что восстановленной площадке, и удалить все связанные с ним виртуальные машины:
$ ncli> pd deactivate-and-destroy-vms name=protection_domain_name
Осторожно! Команда выше удаляет Protection Domain и все виртуальные машины, в него входящие. Не перепутайте кластер (а еще лучше, делать все это под наблюдением технической поддержки).
- Возвращаемся на резервную площадку, выбираем Protection Domain, машины из которого требуется вернуть на основную площадку и нажимаем Migrate;
- Запускаем виртуальные машины на основной площадке.
Теперь как это выглядит на практике:
Основная площадка была восстановлена и запущена после «аварии». Все виртуальные машины на ней присутствуют:

В этот же момент, те же самые виртуальные машины уже некоторое время работают на резервной площадке и с момента начала аварии в них были внесены изменения:
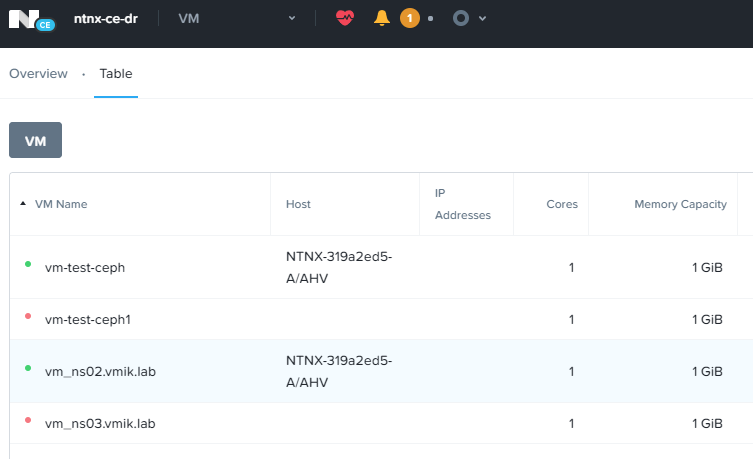
Статус PD на основной площадке сообщает о неудачных попытках репликации, поскольку данный PD активен на резервной площадке:

Теперь, согласно инструкции, выполним удаление Protection Domain test-dr и всех связанных с ним виртуальных машин с основной площадки, на которой ранее был сбой.
Подключаемся к CVM и вводим ранее указанные команды:
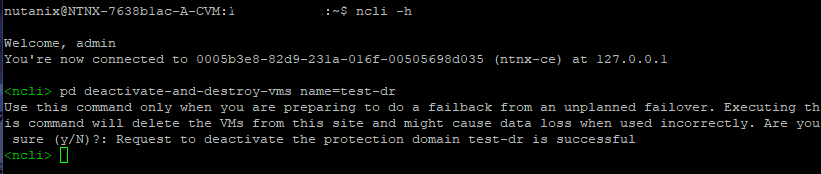
ncli предупреждает, что выполнять данную операцию следуют только в случае, если мы выполняем операцию возврата виртуальных машин и что все виртуальные машины, связанные с данным PD будут удалены.
После ввода команды, в списке задач можно увидеть, что виртуальные машины были удалены, а PD был деактивирован:
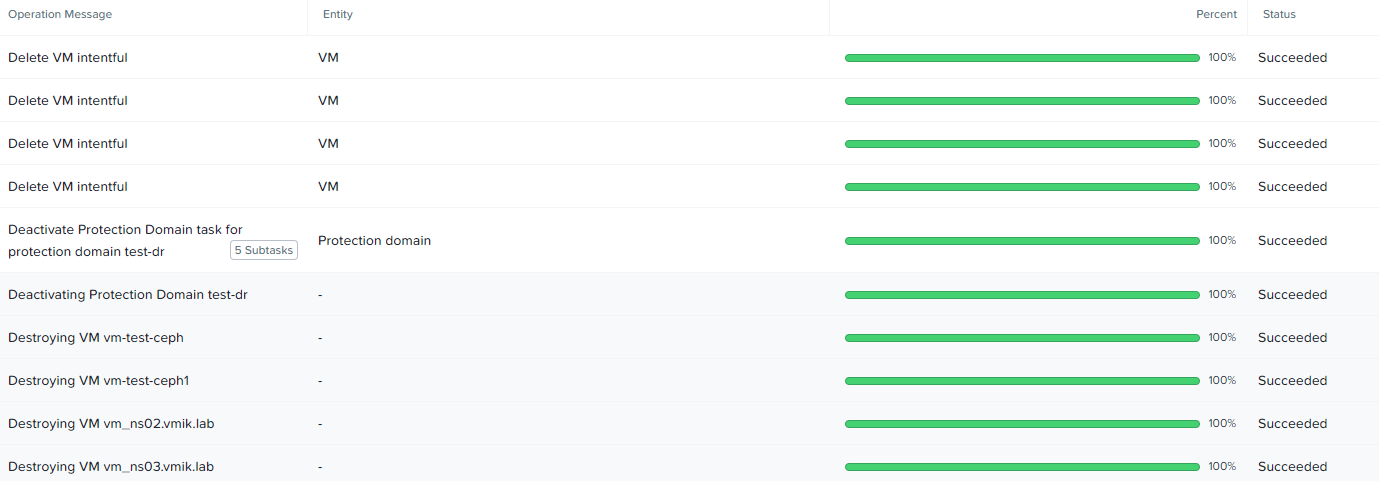
Так же виртуальные машины, относящиеся к деактивированному PD, отсутствуют и в общем списке:
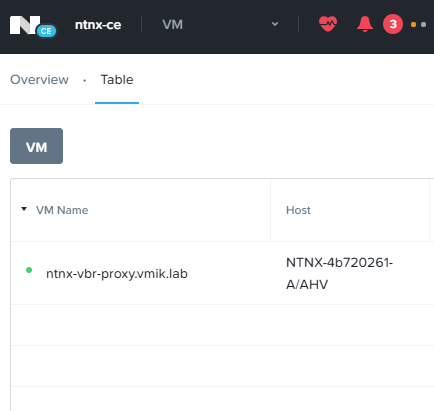
Но продолжают работать на резервной площадке:
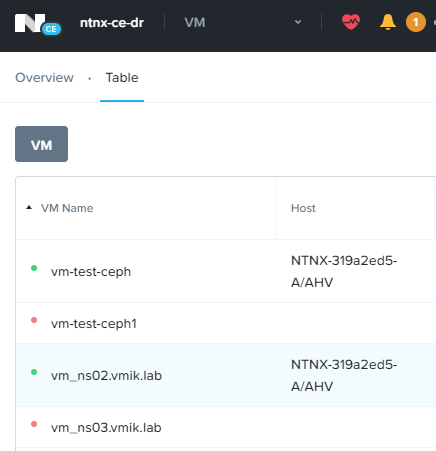
Protection Domain на основной площадке более неактивен:
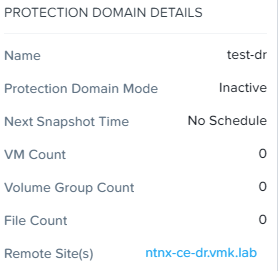
Теперь, когда подготовительные работы выполнены, мы можем выполнить операцию Failback и вернуть виртуальные машины с резервной площадки на основную.
Делается это аналогично операции с плановым переключением. В секции Data Protection резервной площадки выбираем нужный PD и запускаем процесс миграции на основную площадку:
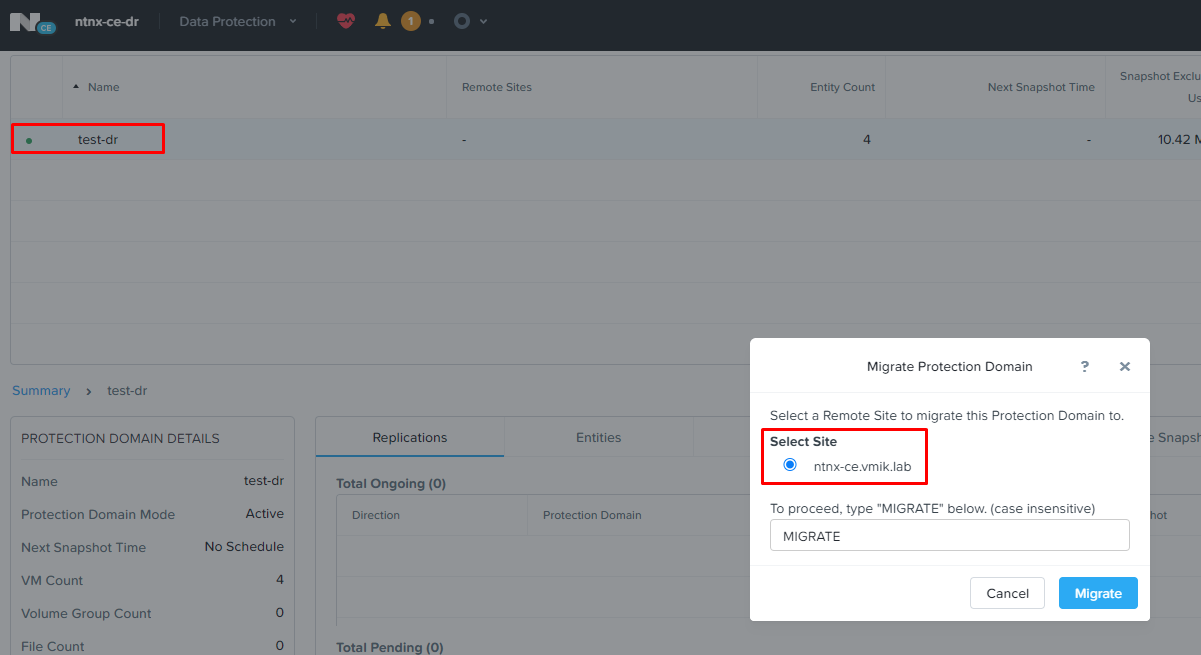
Далее все пройдет уже по знакомому сценарию. Виртуальные машины на резервной площадке будут выключены, изменения будут реплицированы на основную площадку.
Теперь на резервной площадке виртуальные машины отсутствуют:
А на основной, наоборот, присутствуют:
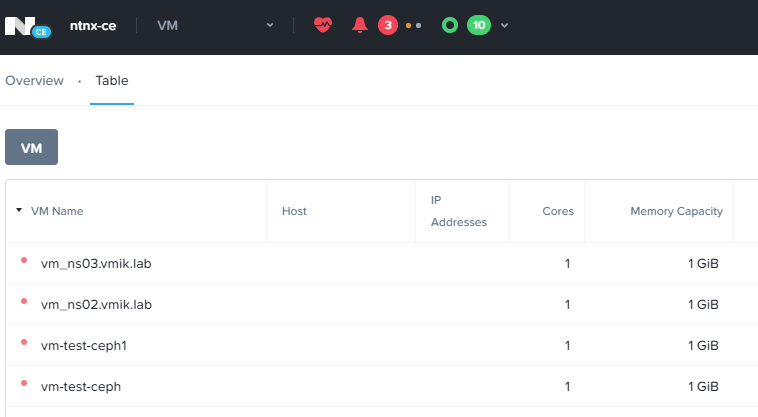
Изменения, внесенные в виртуальную машину на резервной площадке, были успешно перенесены:
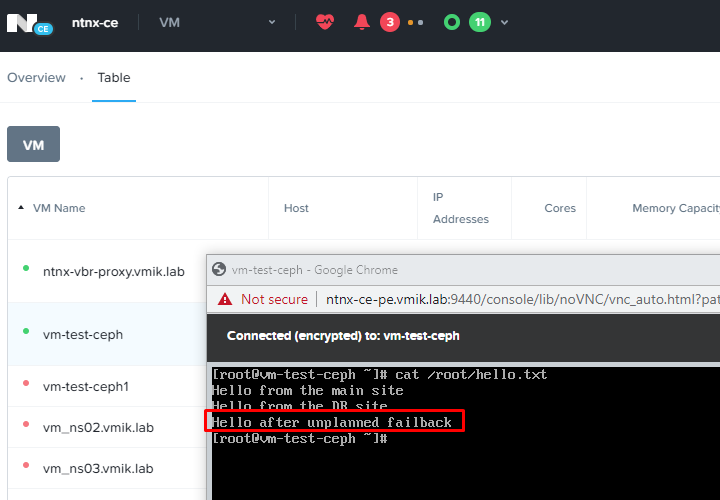
Protection Domain в активном состоянии теперь находится только на основной площадке и все изменения, как и раньше, продолжают реплицироваться на резервную площадку:
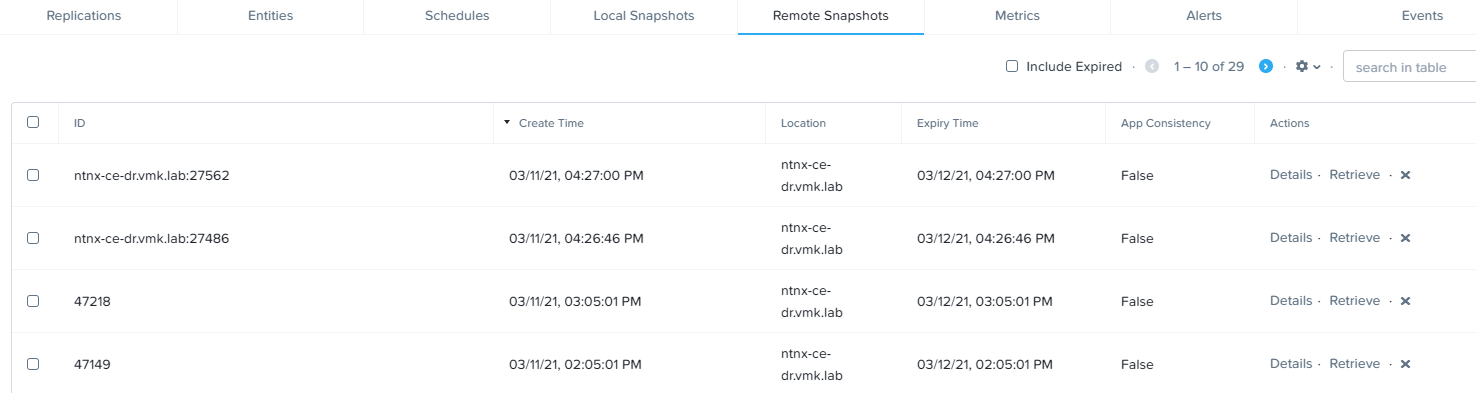
В качестве заключения:
Как можно заметить, процедуры Failover и Failback выполняются достаточно просто. Однако, я настоятельно рекомендую в первую очередь ознакомиться с официальной документацией и проконсультироваться с технической поддержкой, а статью использовать только в качестве картинок и примеров того, что можно ожидать от выполнения определенных действий, а не как непосредственное руководство к действию.
Все команды выполняются на свой страх и риск. Семь раз проверь – один раз введи.
И не забывайте, что репликация на удаленной площадку – дело хорошее, но резервная копия должна быть всегда.
![]()