Пожалуй, каждый администратор систем Nutanix знает про командный интерфейс aCli (Acropolis Command Line Interface), который позволяет выполнять ряд задач по управлению кластером, а также предоставляет довольно неплохие возможности по автоматизации и ускорению некоторых рутинных процессов.
Несмотря на то, что основным инструментом администрирования является интерфейс Prism Element и Prism Central, в данной заметке хочется обратить внимание на некоторые интересные команды aCli, которые позволяют выполнять операции, зачастую недоступны через Web (но это не точно).
Экзамен Nutanix Certified Associate по версии 5.15, который был выпущен не так давно в свет, теперь является начальным этапом в сертификационном треке Nutanix, а это означает то, что всем желающим начать сертификацию по решениям Nutanix, необходимо будет начать со сдачи данного экзамена.
Год подходит к концу, и было бы неплохо начать следующий с получения сертификата NCA 🙂
О том, что стоит почитать, и как подготовиться к сдаче экзамена, ниже.
Хранить логи не только на самом оборудовании, но и удаленно, это всегда хорошая практика. Современные системы позволяют не просто хранить журналы оборудования, систем и сервисов, но также анализировать их и, при необходимости, информировать администраторов о наличии в логах записей, требующих внимания.
Большинство Linux систем используют rsyslog для отправки своих журналов в места их длительного хранения и Nutanix здесь не является исключением.
К сожалению, в отличии от интерфейса Prism Central, в котором настройка отправки журналов возможна из веб-интерфейса, аналогичной функции в Prism Element нет и потребуется прибегнуть к командной строке для настройки.
Ниже о том, как включить rsyslog в кластере Nutanix.
На данном сайте можно периодически встретить посты про Veeam, а можно про Nutanix. Но постов, совмещающих оба этих продукта, еще не было, несмотря на то, что повод уже очень давно есть.
Настало время исправить данный недочет и сделать пару резервных копий виртуальных машин Nutanix на базе гипервизора AHV с помощью VBR.
Ниже мы пройдемся по всем этапам настройки системного копирования, бэкапа и, конечно же, восстановления.
Nutanix пересматривает свою существующую сертификацию и, в дополнении к весеннему ребрендингу сертификации NCP и NCAP, которые превратились в NCP-MCI и NCAP-MCI, в ближайшее время ожидается много нового в плане сертификации и обучения.
Первое – станет доступен новый экзамен начального уровня, который сейчас находится на стадии бета-тестирования, NCA – NutanixCertifiedAssociate. Данный экзамен проверит базовые знания сдающего относительно функционирования решений Nutanix и базового администрирования.
Таким образом порядок сертификации будет выглядеть следующим образом – NCA – NCP – NCM – NPX.
В дополнение к существующему сертификационному треку Multicloud Infrastructure планируется добавить три новых. Общий список будет выглядеть вот так:
Digital HCI Services – Multicloud Infrastructure;
Data Center Services – Data Services, Security & Governance, Business Continuity;
В ближайшее время должны появиться еще два новых экзамена:
Nutanix Certified Professional – End User Computing (NCP-EUC) – развертывание систем VDI на базе решений Nutanix;
Nutanix Certified Professional – Data Services (NCP-DS) – Работа с Files, Objects и Volumes.
Кроме сертификации, на портале Nutanix University появились новые обучающие курсы и планы по обучению (группа курсов, связанных общей тематикой, или же Learning Plan).
В дополнении к существующим курсам Enterprise Cloud Administration (ECA) и Advanced Administration & Performance Management (AAPM), которые могут быть использованы для подготовки к экзаменам NCP и NCM, добавился курс Nutanix Hybrid Cloud Fundamentals, который покрывает основы AOS, управления кластером, хранением, защитой данных и т.д. Данный курс, очевидно, подготавливает к сдаче нового экзамена NCA.
И новые Learning Plans:
Nutanix Multicloud Infrastructure– включает в себя темы от конфигурирования кластера до оптимизации и траблшутинга. Однозначно полезен при подготовке к экзаменам Multicloud Infrastructure;
Enterprise Cloud Solutions – Группа онлайн-курсов по экосистеме Nutanix. Начиная от AOS, заканчивая такими решениями как Nutanix Mine и Karbon. Очевидно будет полезет при подготовке к экзаменам из треков DevOps и Data Center Services.
Вот такие, достаточно интересные и перспективные изменения, которые мотивируют изучать больше и сертифицироваться.
При этом стоит помнить, что онлайн-курсы на Nutanix University бесплатны и доступны для изучения в любой удобный момент.
Если говорить о разграничении прав доступа в Prism Element – базовом инструменте доступа и управления кластером Nutanix и его содержимым, то оно представлено всего тремя доступными ролями:
Viewer – пользователь имеет право просматривать содержимое всего кластера, но не может его изменять;
Cluster Admin – пользователь имеет право управлять всеми элементами кластера, но не может управлять пользователями;
User Admin – максимальные привилегии. Пользователь может управлять всеми элементами кластера, а также пользователями.
Данная схема работает хорошо, когда у кластера один администратор и не требуется каких-либо разграничений в доступе.
Но что делать, если, например, необходимо разграничить доступ более жестко и предоставить одной группе пользователей доступ к управлению одной частью виртуальных машин, а другой группе – ко второй?
К сожалению, малогибкие возможности Prism Element не позволяют осуществлять подобные разграничения и тут в дело вступает мощный инструмент по централизованному управлению и мониторингу кластеров Nutanix – Prism Central.
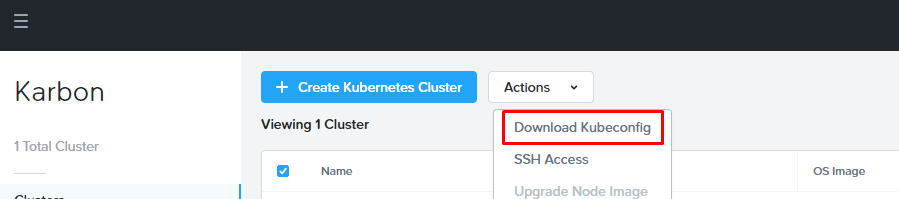
В процессе эксплуатации кластеров Kubernetes на базе Nutanix Karbon одним из первых моментов, с чем приходиться столкнуться – получение непосредственного доступа к управлению Kubernetes.
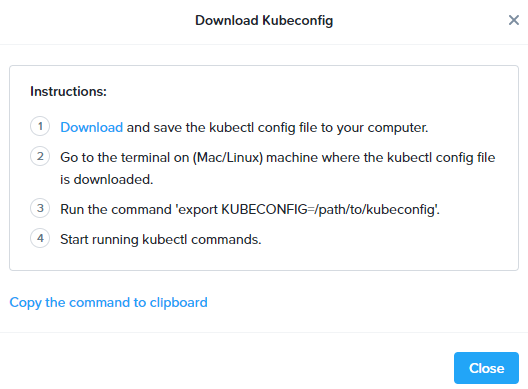
Сделать это достаточно просто. В интерфейсе Karbon необходимо выбрать требуемый кластер и с помощью пункта меню Actions загрузить файл Kubeconfig.
На машине, с которой планируется управление кластером, необходимо установить kubectl версии аналогичной той, которая развернута с помощью Nutanix Karbon. Далее, следуя инструкции разместить файл на машине, с которой планируется подключение к кластеру и использовать переменную KUBECONFIG, либо разместить файл в /home/user/.kube под именем config.
На этом можно было бы закончить, но здесь есть моменты, на которые стоит обратить внимание.
На днях посчастливилось протестировать Nutanix Karbon, который позволяет без каких-либо трудозатрат развернуть на площадке Nutanix готовый к использованию кластер Kubernetes.
Процесс развертывания крайне прост и через ~20-30 минут в моем распоряжении был готовый к использованию кластер.
Естественно, в первую очередь захотелось развернуть простейший «Hello World» из местного реестра на базе Harbor, и проверить работоспособность, но первый деплой был, как говорится, комом.
Время от времени приходится прибегать к процедуре замены дисков на нодах Nutanix серии NX, и хоть это и крайне простая операция, на некоторые моменты можно обратить внимание.
В процессе обслуживания кластеров Nutanix, иногда приходится прибегнуть к процедуре остановки виртуальных машин CVM, которые являются неотъемлемой частью кластера и предоставляют дисковые ресурсы виртуальным машинам и не только.
Сразу отмечу, что не стоит останавливать виртуальную машину следующими способами:
Классической Linux командой shutdown из операционной системы CVM;
С гипервизора AHV с помощью virsh (я удивился, когда увидел подобный совет на одном форуме).
Каждый из вышеуказанных типов отключения CVM приводит к «внеплановой», с точки зрения кластера, остановке, что может вызвать временные (скорее всего не сильно заметные) задержки в дисковом трафике у ряда виртуальных машин.
Для корректной остановки CVM Nutanix необходимо использовать специально подготовленный скрипт cvm_shutdown, который находится на каждой CVM в кластере. Аргументы данного скрипта аналогичны аргументам, которые можно передать стандартной команде shutdown.
Если обратиться к исходному коду скрипта, можно определить, что он, в отличии от классического отключения ОС, выполняет ряд операций, способствующих корректному отключению CVM с минимизацией влияния на виртуальные машины.
cvm_shutdown:
Логирует свои действия;
Выполняет проверку состояния кластера на наличие запущенной процедуры обновления;
Переводит дисковый трафик на другую доступную CVM;
Выполняет остановку процессов CVM и отключает\перезагружает ОС, в зависимости от переданных аргументов.
Вот что сказано в документации к скрипту: This script signals HA when shutting down the CVM (Controller VM) to forward the storage traffic to another healthy CVM. Instead of using “sudo shutdown” or “sudo reboot” commands, this script should be used to minimize I/O hit in user VMs running on the present hypervisor host.
Как видно из описания, использование данного скрипта минимизирует проблемы с дисковым вводом-выводом виртуальных машин, использующих данную CVM и является в большинстве случаев единственно правильным вариантом остановки.