Периодически возникают мысли о повышении доступности компонентов Veeam. Если с прокси сервером все понятно – добавляй новые и формируй отказоустойчивость за счет избыточности, то с репозиториями так не получится. Виртуальные репозитории частично лишены этой проблемы, поскольку механизм HA довольно быстро вернет виртуальную машину в строй после сбоя хоста. С репозиториями на физических серверах все немного иначе и если сервер с бэкапами умер, то здесь уже нужно будет немного поработать руками, что займет большее время.
С выходом v11, значительным обновлением компонента Transport и активной работой Veeam в направлении Linux систем, я решил попробовать воплотить давние мысли по повышению доступности репозитория.
Данная статья исключительно Proof of Concept и является лишь подтверждением, что так будет работать. Подобные инсталляции крайне не рекомендую использовать в продуктивной среде без надлежавшего тестирования, я же особых тестов не проводил и неизвестно как предлагаемое решение будет работать в долгосрочной перспективе.
Схема реализации достаточно простая:
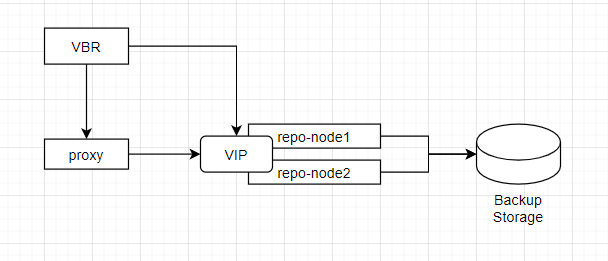
У нас имеется стандартная связка:
- Сервер Veeam Backup and Replication под управлением Windows Server;
- Veeam Proxy под управлением Windows/Linux;
- Два сервера для будущего Veeam Repository, к которым подключены дисковые ресурсы с СХД под управлением CentOS 7.9.
Репозитории работают в режиме active-passive, т.е. одномоментно IP-адрес, по которому доступен репозиторий работает только на одной ноде, также только к этой ноде подключены дисковые ресурсы.
В случае выхода из строя активной ноды, дисковые ресурсы, службы, а также IP адрес автоматически поднимаются на второй (passive) ноде.
Процедуру настройки можно разделить на пять этапов:
- Подготовка систем, обновление, настройка файрволла и т.п.;
- Подача дисковых ресурсов на ноды кластера;
- Настройка кластера с помощью Pacemaker, создание общих ресурсов;
- Настройка Linux машины в Veeam, создание репозитория;
- Проверка тестирования и восстановления.
Итак, приступим.
На текущий момент у меня уже установлен сервер Veeam Backup, на котором так же запущен Veeam Proxy.
Для экспериментов я создал две виртуальные машины: vbr-repo-1.vmik.lab и vbr-repo-2.vmik.lab на которые установлена операционная система CentOS 7.9 в минимальной версии.
Поскольку это лабораторное окружение, я не буду заморачиваться с настройкой firewalld, selinux и просто их отключу. В продуктивной среде так делать, конечно, не нужно, поэтому требуемый список портов для Veeam можно взять по ссылке, а порты для корректной работы кластера вот по этой.
Также заранее хочу отметить, что здесь не будет детального описания процесса работы кластера pacemaker/corosync и настраиваемых параметров. Эта тема явно не для одной статьи.
Обновляем обе системы:
# yum -y update
Устанавливаем open-vm-tools в случае с виртуальными машинами на vSphere:
# yum -y install open-vm-tools
Отключаем файрволл и переводим SElinux в режим Disabled:
# systemctl disable firewalld# sed -i s/^SELINUX=.*$/SELINUX=disabled/ /etc/sysconfig/selinux
Перезагружаем обе машины после обновлений и внесенных изменений:
# reboot
Подготовительный этап завершен. Переходим к настройке кластера PCS из двух нод.
На двух нодах устанавливаем кластерные пакеты:
# yum install pcs pacemaker fence-agents-all
Теперь нам необходим пользователь, от имени которого будет оперировать кластер. Создаем пользователя на двух нодах и задаем ему пароль (указанный ниже пользователь может присутствовать в системе):
# useradd hacluster# passwd hacluster
Запускаем кластерные сервисы на двух узлах и добавляем их в автозагрузку:
# systemctl enable --now pcsd.service
С первой ноды запускаем процедуру авторизации наших узлов:
# pcs cluster auth vbr-repo-1.vmik.lab vbr-repo-2.vmik.lab
Здесь мы указываем адреса/имена нод кластера, после чего нас попросят указать логин\пароль для взаимодействия. Используем пользователя hacluster, который был создан выше.
Если процедура прошла успешно, мы получим сообщение о том, что оба узла авторизованы:

Создаем и запускаем кластер с именем vbr-repo на двух узлах:
# pcs cluster setup --start --name vbr-repo vbr-repo-1.vmik.lab vbr-repo-2.vmik.lab
# pcs cluster enable --all
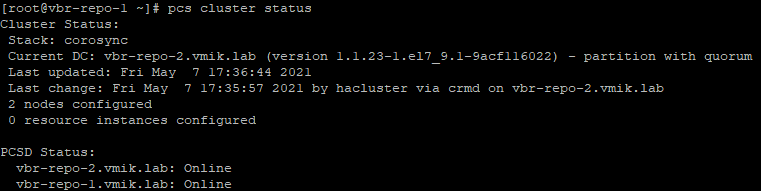
Посмотреть статус кластера:
# pcs cluster status
Если все сделано верно, обе ноды будут отмечены как «Online»:
Теперь, когда мы авторизовали ноды и создали кластер, необходимо настроить механизм STONITH (Shoot The Other Node In The Head) – этот механизм предназначен для того, чтобы «живые» узлы кластера могли отключать\перезагружать и т.п. «неживые», по их мнению, узлы.
Делается это в первую очередь для получения монопольного доступа к общим ресурсам, например, чтобы не возникла ситуация, при которой оба сервера одновременно монтируют один и тот же дисковый ресурс без кластерной файловой системы и портят на нем данные, думая при этом, что его партнер в данный момент мертв и ресурс не использует, и уже во вторую очередь механизм используется для возобновления работоспособности сбойного узла.
Настройка заключается в связке нод кластера с устройствами, которые позволяют управлять питанием этих самых нод, например, iDRAC, iLO, BMC и т.п в случае с физическими серверами. В моем случае, это будет vCenter Server, который позволяет управлять состоянием виртуальных машин.
Просмотреть список всех доступных методов для STONITH:
# pcs stonith list
Посмотреть более детальное описание для конкретного метода (в моем случае fence_vmware_soap:
# pcs stonith describe fence_vmware_soap
Теперь попробуем подключиться к vCenter и получить список виртуальных машин:
# fence_vmware_soap -z -l admin@vmik.lab -p my_password -a vcsa67.vmik.lab -o list --ssl-insecure -o list
Если подключение прошло успешно, вы получите список виртуальных машин и их UUID. Среди списка машин я отмечаю две, которые являются узлами кластера и фиксирую их UUID:

Теперь настроим STONITH. Предварительно его временно отключив:
# pcs property set stonith-enabled=false
# pcs property set no-quorum-policy=ignore
Второй командой мы указали игнорирование кворума и продолжение предоставление ресурсов в случае его отсутствия.
Настраиваем ресурс, который связывает узлы кластера с виртуальными машинами в vCenter:
# pcs stonith create fence_vbr_vms fence_vmware_soap ipaddr=vcsa67.vmik.lab \
ssl=1 ssl_insecure=1 login=admin@vmik.lab passwd= my_password pcmk_reboot_action=on \
pcmk_host_map="vbr-repo-1.vmik.lab:42356049-6020-2ea0-0bd9-11362ef785e7 vbr-repo-2.vmik.lab:423576b3-f216-b7e7-aba6-9419bcb72a24"
Важный в данном моменте параметр – pcmk_host_map, где выстраивается соответствие узлов кластера по их именам с UUID виртуальных машин, полученных ранее. Здесь важно быть внимательным и не ошибиться, поскольку в будущем легко можно отключить что-то не то, изначально некорректно настроив данный момент.
Включаем STONITH обратно:
# pcs property set stonith-enabled=true
Проверим результат предыдущих команд:
# pcs stonith show

Если все сделано верно, мы увидим новый STONITH ресурс, который будет находиться в состоянии Started. Если он находится в статусе Stopped, следует обратиться к логам. Возможно, не удалось установить соединение, неверный логин\пароль и т.п.
На этом этапе мы закончили базовую конфигурацию кластера, состоящего из двух виртуальных машин и настроили STONITH для того, чтобы в случае возникновения проблем с доступностью узлов, они могли «перезагружать» друг друга, используя vCenter Server.
Следующим шагом мы настроим общие ресурсы в кластере.
В нашем случае общих ресурсов будет несколько:
- Общий диск\лун для двух узлов кластера, на котором будут располагаться компоненты Veeam, которые устанавливаются в /opt/veeam;
- Общий диск\лун на котором будет непосредственно размещен репозиторий и где будут храниться резервные копии;
- Общий IP адрес, по которому репозиторий будет доступен для всех остальных компонентов Veeam.
Для подключения общих дисков, к каждой из виртуальных машин я добавил по SCSI контроллеру:
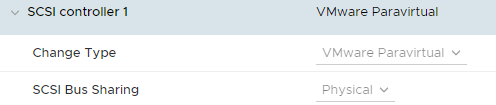
SCSI Bus Sharing переведен в режим «Physical», чтобы виртуальные машины с разных хостов могли иметь доступ к одному и тому же диску.
К данному контроллеру подключено два диска. На 10 и 200Gb, соответственно.
У дисков выставлен флаг Multi-Writer, они подключены в состоянии Independed – Persistent, так же был выбран формат Eager-Zeroed Thick.
Таким образом на двух нодах доступны одни и те же диски:

Настроим LVM и создадим файловые системы на данных дисках. Выполняется данная операция только с одной ноды (в моем случае с первой).
# pvcreate /dev/sdb /dev/sdc
# vgcreate vg_vbr /dev/sdb
# vgcreate vg_repo /dev/sdc
Создаем логические тома:
# lvcreate -l+100%FREE -n lv_vbr vg_vbr
# lvcreate -l+100%FREE -n lv_repo vg_repo
И файловые системы:
mkfs.xfs /dev/vg_vbr/lv_vbr
mkfs.xfs /dev/vg_repo/lv_repo
Настроим LVM для работы в кластере на двух нодах:
# lvmconf --enable-halvm --services --startstopservices
Теперь необходимо подправить файл lvm.conf и добавить в него параметр volume_list, который определяет volume groups, которые будут активированы при старте ОС.
В нашем случае активировать необходимо только системную VG, на которой стоит ОС (у меня она называется centos), выше созданные VG активировать не нужно, поскольку это будет выполняться средствами кластера и будет нехорошо, если обе ноды будут пытаться одновременно выполнять данную операцию.
# vi /etc/lvm/lvm.conf
Находим и правим параметр volume_list = [ "centos" ]
Создадим директории на двух узлах кластера. Одну под служебные файлы Veeam, вторую под репозиторий:
# mkdir -p /opt/veeam
# mkdir -p /veeam/repo
И на последок сгенерируем новый образ initramfs и перезагрузим ноды:# dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)# reboot
Теперь перейдем к настройке ресурсов кластера. Ресурсы формируются в группы, которые запускаются на узлах и перемещаются между ними в случае возникновения сбоев на активном узле, либо по команде администратора кластера.
В нашем случае ресурсов четыре – Volume Group, File System, IP Address и Service. У всех ресурсов имеется порядок запуска и его можно редактировать, но лучше сразу создать все в правильном порядке.
Создаем ресурсы для Volume Group:
# pcs resource create "vg_vbr" LVM volgrpname="vg_vbr" exclusive=true --group "vbr"
# pcs resource create "vg_repo" LVM volgrpname="vg_repo" exclusive=true --group "vbr"
Если все сделано верно, ресурсы будут находиться в статусе Started. Проверить это можно с помощью:
# pcs resource show

Теперь создадим ресурс с файловыми системами:
# pcs resource create "fs_vbr" Filesystem device="/dev/mapper/vg_vbr-lv_vbr" directory="/opt/veeam/" fstype="xfs" --group="vbr"
# pcs resource create "fs_repo" Filesystem device="/dev/mapper/vg_repo-lv_repo" directory="/veeam/repo/" fstype="xfs" --group="vbr"
Проверить можно также с помощью pcs resource show. Там же будет видно, где данный ресурс запущен – в моем случае это первая нода. Убедимся в правильности настроек:

Кластер автоматически смонтировал созданные файловые системы в указанные директории.
Создадим еще один ресурс – IP адрес, по которому будут доступны службы Veeam в будущем:
# pcs resource create "ip_vbr" IPaddr2 ip="192.168.22.208" cidr_netmask=”24” nic="ens192" --group="vbr"
Проверить достаточно просто – у нас так же появится новый ресурс, а IP должен отвечать на icmp запросы, если они открыты. Для этого же адреса я создал DNS-запись vbr-repo.vmik.lab.
На текущий момент мы настроили файловые системы, а также общий IP адрес. Теперь отвлечемся ненадолго от кластера и перейдем в консоль VBR.
В консоли VBR, в разделе Managed Servers добавляем новую Linux-машину:
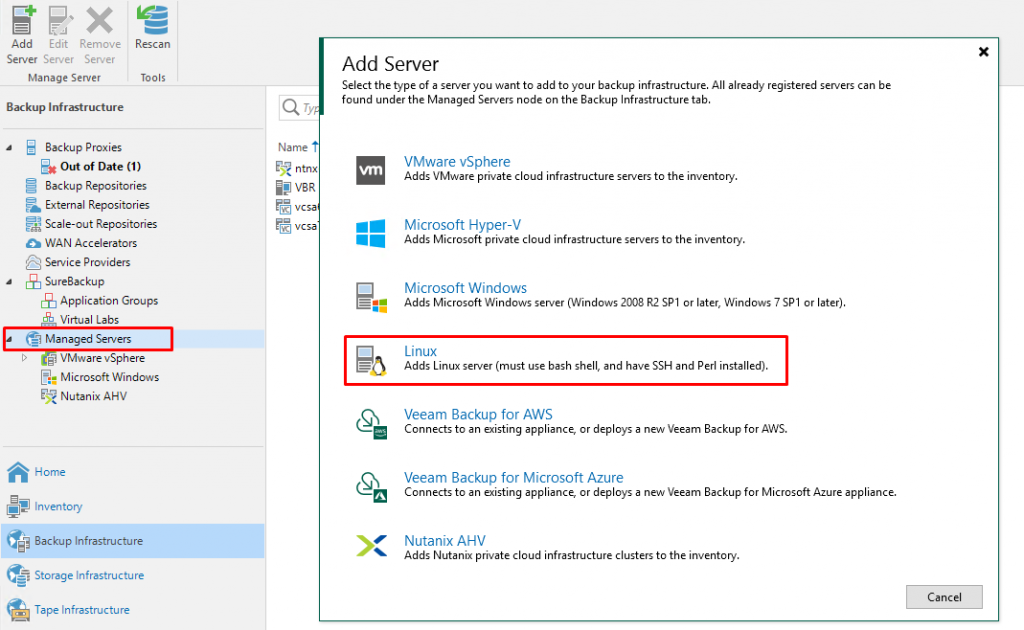
Далее мы указываем IP адрес, который был выбран для созданного выше ресурса. Я же использую DNS-имя, настроенное на IP 192.168.22.208:
Далее указываем логин\пароль для доступа к серверу. В лаборатории я использую логин root:

Veeam сообщает, что будет выполнена установка компонента Veeam Transport:
Клик по Apply. Выполняется добавление сервера и установка компонентов:
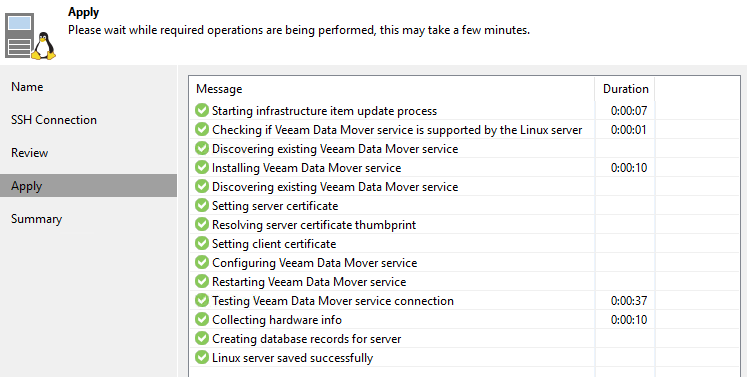
Как итог – у нас добавлен новый сервер Linux, доступ к которому обеспечивается через кластерный IP (в настоящий момент находящийся на первой ноде):
Вернемся на первую ноду и посмотрим на изменения. В /opt/veeam были установлены компоненты транспорта. Теперь, при переключении ресурсов между узлами кластера, файлы транспорта также будет перемещаться на другой узел:
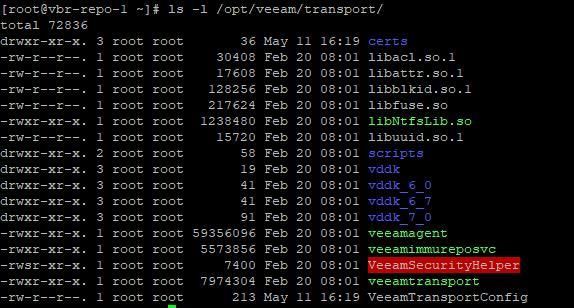
Также на данном узле запущена служба VeeamTransport:
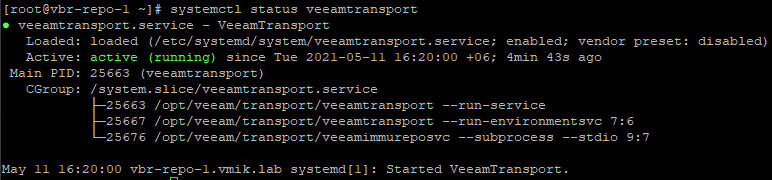
Теперь выполним несколько «грязных приемов». Поскольку фактически компоненты были установлены на одну ноду, на втором узле кластера отсутствуют файлы systemd для запуска службы VeeamTransport. Скопируем:
# scp /etc/systemd/system/veeamtransport.service root@vbr-repo-2.vmik.lab:/etc/systemd/system/
Также, на первой ноде уберем VeeamTransport из автозагрузки и остановим его, поскольку запуском службы в нашем случае должен заниматься кластер:
# systemctl disable --now veeamtransport
Теперь создадим последний ресурс кластера, который будет запускать службу VeeamTransport на активной ноде:
# pcs resource create "svc_veeamtransport" systemd:veeamtransport --group="vbr"
Если все сделано верно, на первой ноде будет запущена служба VeeamTransport (с учетом того, что ранее мы ее остановили). Итоговое состояние ресурсов:

И последний момент по работе с кластером PCS. Изначально, в моем случае ресурсы были созданы на первой ноде. В случае выхода из строя хоста, ресурсы будут перезапущены на второй ноде, что ожидаемо, но, по умолчанию, после возвращения первой ноды в работу, все ресурсы будут автоматически возвращены туда.
Данное поведение может быть нормальным в некоторых ситуациях, но в нашем случае, подобное, пусть и плановое возвращение, может прервать выполняющиеся задачи резервного копирования, поэтому применим настройки constraint для группы ресурсов, указав одинаковый приоритет для двух узлов кластера:
# pcs constraint location vbr prefers vbr-repo-1.vmik.lab=100
# pcs constraint location vbr prefers vbr-repo-2.vmik.lab=100
Теперь, после запуска\остановки хостов, ресурс не будет самостоятельно возвращаться.
Проведем небольшую проверку. Сейчас все ресурсы запущены на первой ноде и проверка статуса Linux хоста в консоли VBR проходит успешно:
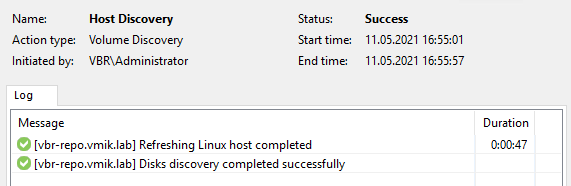
Отключаем виртуальную машину (первую ноду) в консоли vSphere и смотрим, что происходит:
Все ресурсы запустились на второй ноде:

Директории смонтированы там же:
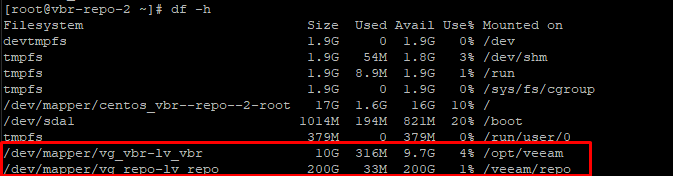
И там же запущена служба VeeamTransport:
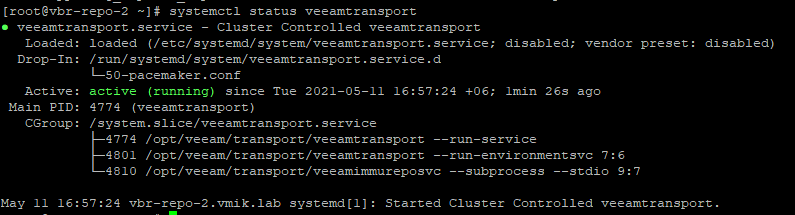
Сделаем rescan машины в консоли VBR и проверим, что она доступна:
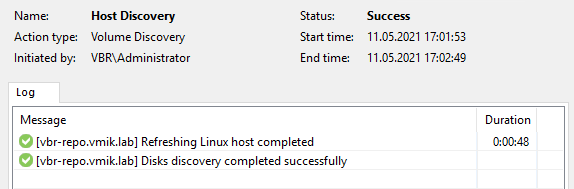
Со стороны консоли VBR все выглядит также, при этом мы знаем, что компоненты Veeam работают на втором узле.
Теперь добавим репозиторий в /veeam/backup. На вкладке Backup Repositories добавляем новый репозиторий Direct attached storage:
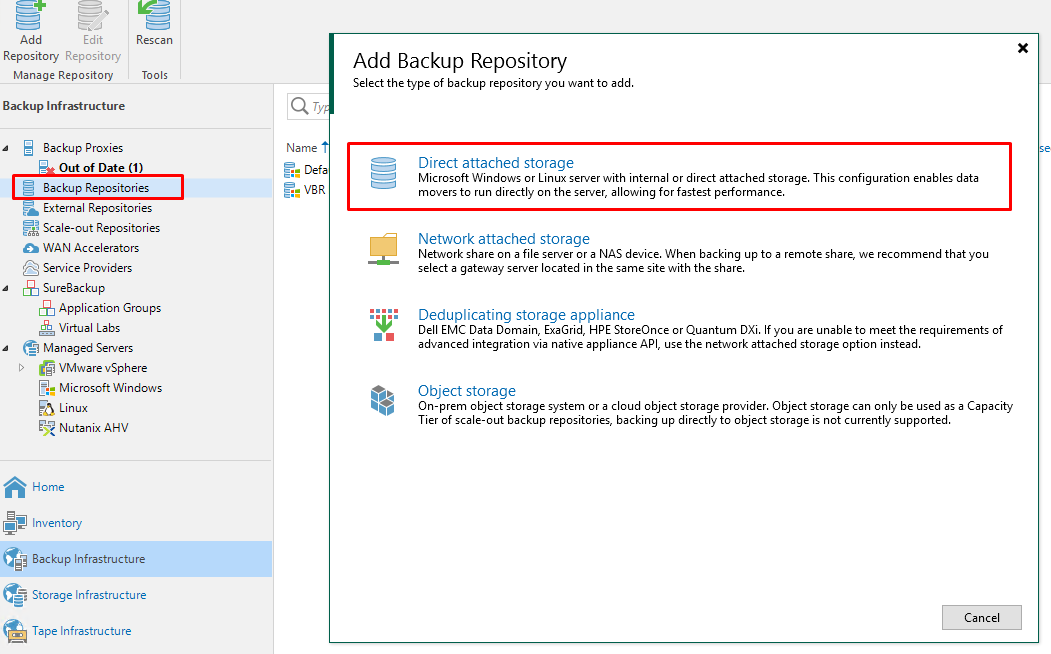
Выбираем Linux, указываем название:
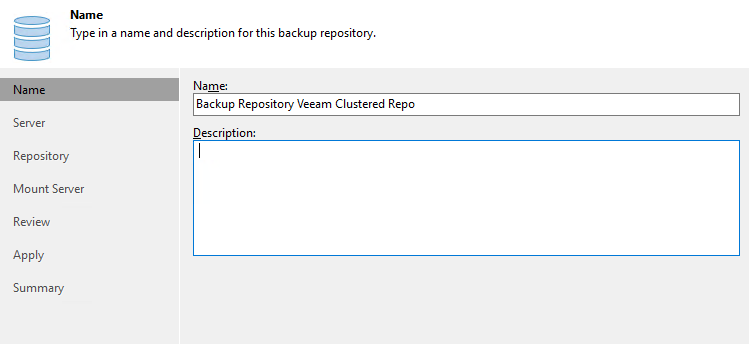
Далее выбираем наш Linux хост:
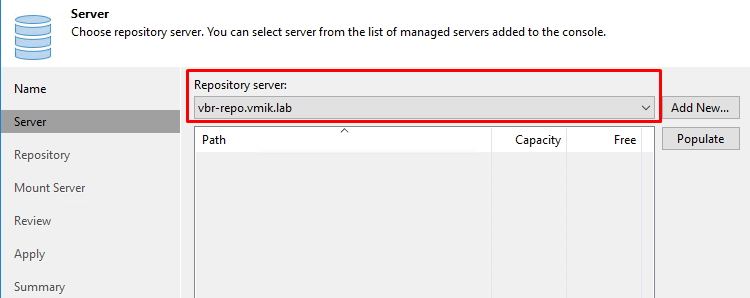
Указываем путь к разделу, на котором планируем хранить резервные копии:
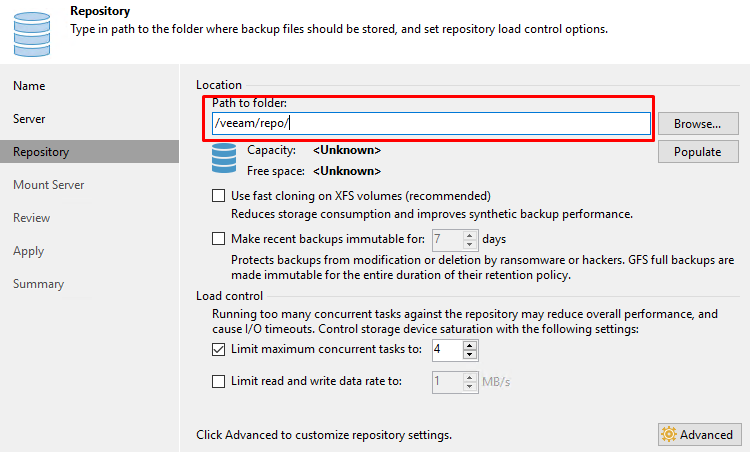
И убеждаемся, что создание репозитория проходит успешно:

Репозиторий доступен в общем списке:

Теперь создаем задачу резервного копирования, настроенную на наш новый репозиторий и запускаем полный бэкап. В моем случае все ресурсы кластера работают на втором узле.
Итак, первый полный бэкап, ожидаемо, прошел успешно:
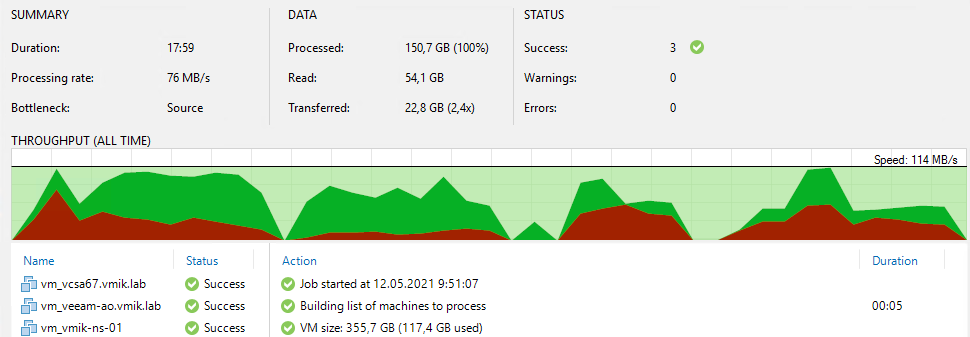
И файлы резервных копий находятся в /veeam/backup на втором узле:

Теперь запустим инкрементальный бэкап и сымитируем «падение» рабочей (второй) ноды где-то по середине.
Чуда, естественно, не произошло и задача резервного копирования была остановлена с ошибкой:

Ресурсы в свою очередь переехали на первую ноду. Там же можно увидеть появившийся vib файл от сбойной задачи:

Перезапустим задачу. Теперь в работе первая нода:

Как можно заметить, перезапуск прошел успешно. Было выполнено только резервное копирование сбойных виртуальных машин. И цель достигнута – VBR корректно отработал с репозиторием, предоставленным с другого узла кластера.
Попробуем восстановить одну из VM. Для примера я беру виртуальную машину, резервное копирование которой ранее обрывалось.
Восстановление из последней инкрементальной копии прошло успешно:
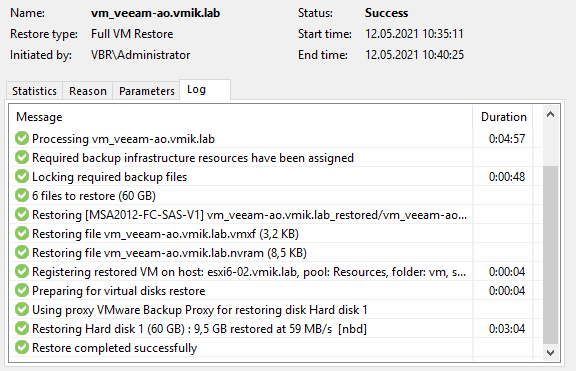
Теперь попробуем то же самое, но отключим активную ноду репозитория (первая) в процессе восстановления:
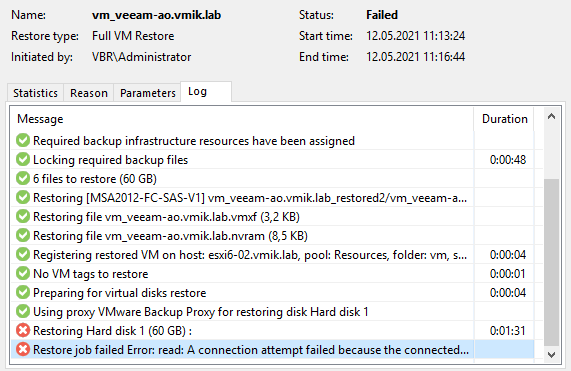
Ожидаемо, восстановление завершилось с ошибкой. Справедливости ради, я перезапустил процедуру восстановления еще раз и оно прошло успешно.
В качестве заключения:
Еще раз напомню, что писалась эта статья исключительно из интереса – будет так работать, или не будет, и это не призыв к какому-либо действию.
В ходе тестирования я несколько раз получил абсолютно нерабочие бэкапы после отключения\включения репозиториев – в большинстве случаев был поврежден файл метаданных. Не берусь утверждать, что непосредственно кластер к этому имеет какое-то отношение, но исключать этого я не могу.
Как видно из статьи – запустить «кластерный» репозиторий можно, но это не спасает от остановки выполняющихся задач резервного копирования – задачи все равно нужно будет перезапускать, поэтому, для виртуальных репозиториев особого смысла в подобных решениях я не вижу. Механизм HA все равно перезапустит виртуальную машину, на которой настроен репозиторий и через пару минут он будет доступен (возможно даже быстрее, чем задача упадет со статусом Failed).
Для физических серверов репозиториев здесь, может быть, и есть какая-то необходимость, но опять же все необходимо тщательно и многократно тестировать, чего я, конечно же, не делал.
![]()